
هوش مصنوعی مولد بسیار محبوب است، اما یک مدل زبان بزرگ چگونه کار می کند؟
مدلهای زبان بزرگ (LLM) فناوری زیربنایی هستند که به رشد شهابآمیز چترباتهای هوش مصنوعی مولد کمک کردهاند. ابزارهایی مانند ChatGPT، Google Bard، و Bing Chat همگی به LLM برای ایجاد پاسخهای انسانمانند به درخواستها و سؤالات شما متکی هستند.
اما LLM چیست و چگونه کار می کند؟ در اینجا ما قصد داریم LLM ها را رمزگشایی کنیم.
مدل زبان بزرگ چیست؟
به زبان ساده، LLM یک پایگاه داده عظیم از داده های متنی است که می تواند برای ایجاد پاسخ های انسان مانند به درخواست های شما ارجاع داده شود. متن از طیف وسیعی از منابع می آید و می تواند به میلیاردها کلمه برسد.
از جمله منابع رایج داده های متنی مورد استفاده عبارتند از:
- ادبیات: LLM ها اغلب حاوی حجم عظیمی از ادبیات معاصر و کلاسیک هستند. این می تواند شامل کتاب، شعر و نمایشنامه باشد.
- محتوای آنلاین: یک LLM اغلب حاوی یک مخزن بزرگ از محتوای آنلاین، از جمله وبلاگ ها، محتوای وب، پرسش ها و پاسخ های انجمن و سایر متن های آنلاین است.
- اخبار و امور جاری: برخی، اما نه همه، LLM ها می توانند به موضوعات خبری فعلی دسترسی داشته باشند. برخی از LLM ها، مانند GPT-3.5، از این نظر محدود هستند.
- رسانه های اجتماعی: رسانه های اجتماعی منبع عظیمی از زبان طبیعی را نشان می دهند. LLM ها از متن های سیستم عامل های اصلی مانند فیس بوک، توییتر و اینستاگرام استفاده می کنند.
البته، داشتن یک پایگاه داده عظیم از متن یک چیز است، اما LLM ها باید آموزش ببینند تا آن را درک کنند تا پاسخ هایی شبیه به انسان ایجاد کنند. نحوه انجام این کار همان چیزی است که در ادامه به آن می پردازیم.
LLM ها چگونه کار می کنند؟
چگونه LLM ها از این مخازن برای ایجاد پاسخ های خود استفاده می کنند؟ اولین قدم تجزیه و تحلیل داده ها با استفاده از فرآیندی به نام یادگیری عمیق است.
یادگیری عمیق برای شناسایی الگوها و تفاوت های ظریف زبان انسان استفاده می شود. این شامل به دست آوردن درک گرامر و نحو است. اما مهم این است که شامل زمینه نیز می شود. درک زمینه بخش مهمی از LLM است.
بیایید به مثالی نگاه کنیم که چگونه LLM ها می توانند از زمینه استفاده کنند.
درخواست در تصویر زیر به دیدن خفاش در شب اشاره می کند. از اینجا، ChatGPT فهمید که ما در مورد یک حیوان صحبت می کنیم و نه، برای مثال، یک چوب بیسبال. البته، رباتهای چت دیگر مانند بینگ چت یا Google Bard ممکن است پاسخی کاملاً متفاوت به این موضوع بدهند.
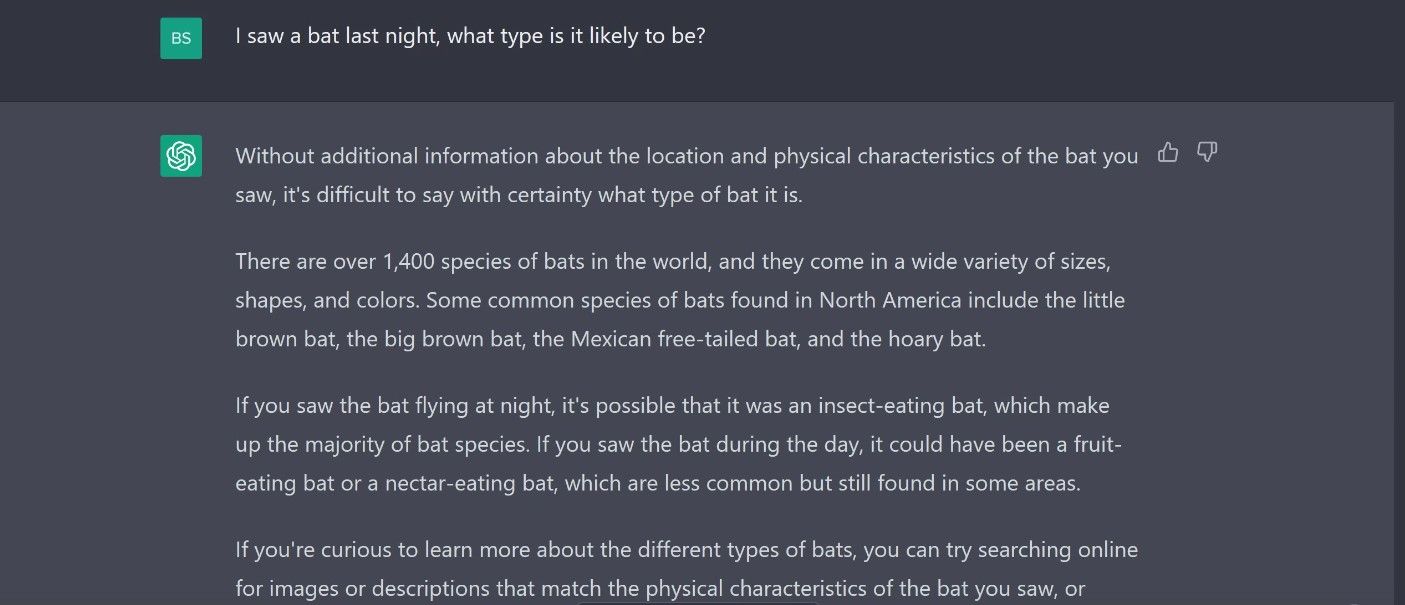
با این حال، خطا ناپذیر نیست، و همانطور که این مثال نشان می دهد، گاهی اوقات شما نیاز به ارائه اطلاعات اضافی برای دریافت پاسخ مورد نظر دارید.
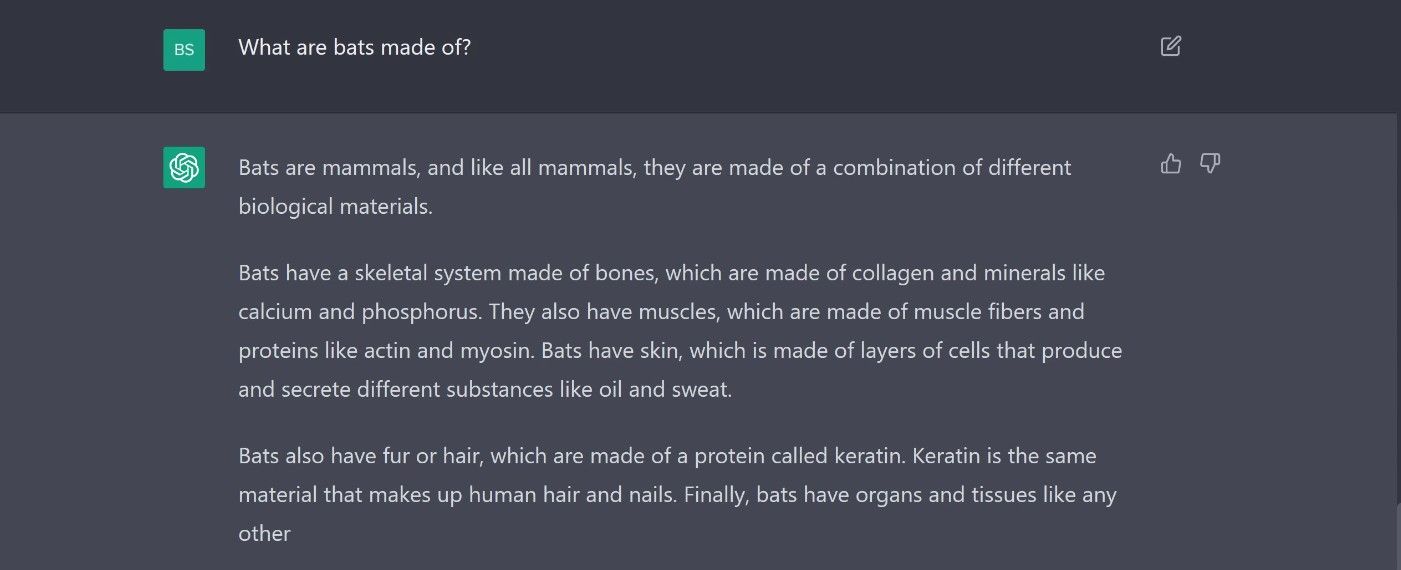
در این مثال، ما عمداً کمی توپ منحنی پرتاب کردیم تا نشان دهیم که متن چقدر راحت از دست میرود. اما انسانها نیز میتوانند زمینه سؤالات را اشتباه درک کنند، و فقط به یک تذکر اضافی برای تصحیح پاسخ نیاز دارد.
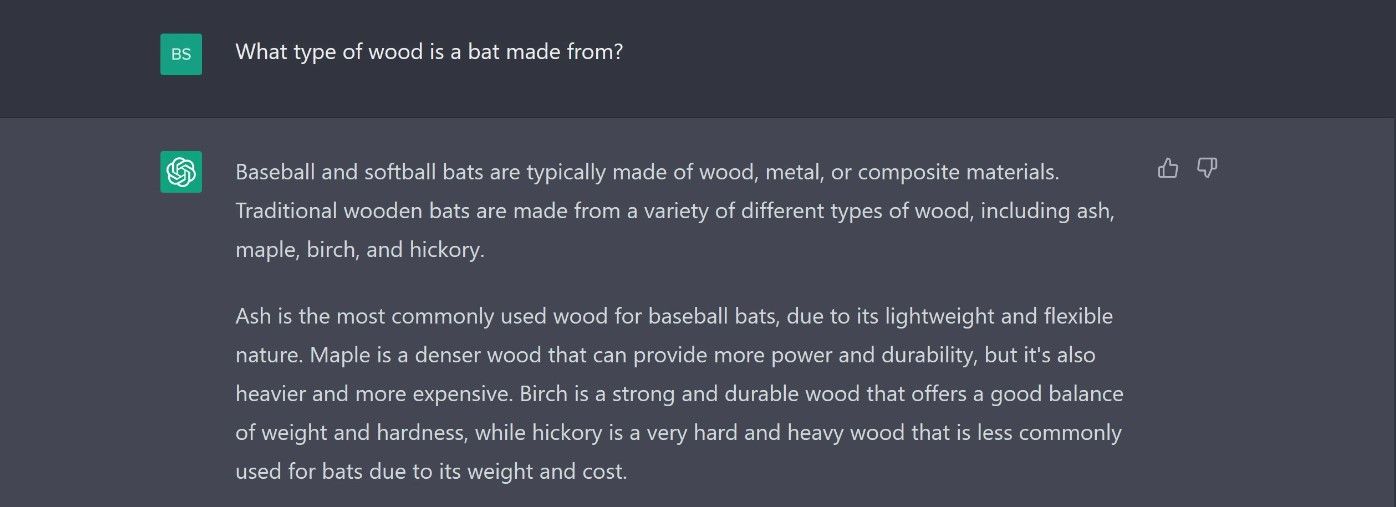
برای تولید این پاسخ ها، LLM ها از تکنیکی به نام تولید زبان طبیعی (NLG) استفاده می کنند. این شامل بررسی ورودی و استفاده از الگوهای آموخته شده از مخزن داده آن برای ایجاد یک پاسخ مناسب و متناوب است.
اما LLM عمیق تر از این است. آنها همچنین می توانند پاسخ ها را متناسب با لحن احساسی ورودی تنظیم کنند. هنگامی که با درک زمینه ای ترکیب می شوند، این دو جنبه محرک های اصلی هستند که به LLM ها اجازه می دهند پاسخ هایی شبیه به انسان ایجاد کنند.
به طور خلاصه، LLM ها از یک پایگاه داده متنی عظیم با ترکیبی از تکنیک های یادگیری عمیق و NLG برای ایجاد پاسخ های انسان مانند به درخواست های شما استفاده می کنند. اما محدودیت هایی برای آنچه که این می تواند به دست آورد وجود دارد.
محدودیت های LLM چیست؟

LLM ها نشان دهنده یک دستاورد فن آوری چشمگیر است. اما این فناوری تا کامل شدن فاصله زیادی دارد و هنوز محدودیتهای زیادی برای دستیابی به آنها وجود دارد. برخی از مهمترین این موارد در زیر ذکر شده است:
- درک متنی: ما این را به عنوان چیزی که LLM ها در پاسخ های خود می گنجانند ذکر کردیم. با این حال، آنها همیشه آن را به درستی دریافت نمی کنند و اغلب قادر به درک زمینه نیستند، که منجر به پاسخ های نامناسب یا صرفاً اشتباه می شود.
- سوگیری: هر گونه سوگیری موجود در داده های آموزشی اغلب می تواند در پاسخ ها وجود داشته باشد. این شامل سوگیری نسبت به جنسیت، نژاد، جغرافیا و فرهنگ است.
- عقل سلیم: کمیت کردن عقل سلیم دشوار است، اما انسان ها این را از سنین پایین به سادگی با تماشای دنیای اطراف خود می آموزند. LLM ها این تجربه ذاتی را ندارند تا دوباره به آن بازگردند. آنها فقط آنچه را که از طریق داده های آموزشی به آنها ارائه شده است می فهمند، و این به آنها درک درستی از دنیایی که در آن وجود دارند نمی دهد.
- یک LLM فقط به اندازه داده های آموزشی آن خوب است: هرگز نمی توان دقت را تضمین کرد. ضرب المثل قدیمی کامپیوتری “آشغال داخل، زباله بیرون” این محدودیت را کاملاً خلاصه می کند. LLM ها فقط به اندازه ای هستند که کیفیت و کمیت داده های آموزشی آنها به آنها اجازه می دهد.
همچنین این بحث وجود دارد که نگرانی های اخلاقی را می توان محدودیتی برای LLM در نظر گرفت، اما این موضوع خارج از محدوده این مقاله است.
3 نمونه از LLM های محبوب
پیشرفت مستمر هوش مصنوعی اکنون عمدتاً توسط LLM ها پشتیبانی می شود. بنابراین، در حالی که آنها دقیقاً یک فناوری جدید نیستند، مطمئناً به نقطه حرکت بحرانی رسیده اند و اکنون مدل های زیادی وجود دارد.
در اینجا تعدادی از پرکاربردترین LLM ها آورده شده است.
1. GPT
ترانسفورماتور از پیش آموزش دیده مولد (GPT) شاید شناخته شده ترین LLM باشد. GPT-3.5 پلتفرم ChatGPT مورد استفاده برای نمونه های این مقاله را تقویت می کند، در حالی که جدیدترین نسخه، GPT-4، از طریق اشتراک ChatGPT Plus در دسترس است. مایکروسافت همچنین از آخرین نسخه در پلتفرم بینگ چت خود استفاده می کند.
2. LaMDA
این اولین LLM است که توسط Google Bard، چت ربات هوش مصنوعی گوگل استفاده می شود. نسخه ای که Bard در ابتدا با آن عرضه شد به عنوان یک نسخه “لایت” از LLM توصیف شد. تکرار قدرتمندتر PalM LLM جایگزین این شد.
3. برت
BERT مخفف Bi-directional Encoder Representation from Transformers است. ویژگی های دوطرفه مدل BERT را از سایر LLM ها مانند GPT متمایز می کند.
تعداد زیادی LLM توسعه یافته اند و شاخه های LLM های اصلی رایج هستند. با توسعه آنها، پیچیدگی، دقت و ارتباط آنها همچنان افزایش می یابد. اما آینده برای LLM ها چه خواهد بود؟
آینده LLM
اینها بدون شک نحوه تعامل ما با فناوری را در آینده شکل خواهند داد. جذب سریع مدل هایی مانند ChatGPT و Bing Chat گواهی بر این واقعیت است. در کوتاه مدت، بعید است که هوش مصنوعی جایگزین شما در محل کار شود. اما هنوز در مورد اینکه اینها در آینده چه نقشی در زندگی ما خواهند داشت، تردید وجود دارد.
استدلال های اخلاقی ممکن است هنوز در مورد نحوه ادغام این ابزارها در جامعه حرفی برای گفتن داشته باشند. با این حال، با کنار گذاشتن این موضوع، برخی از پیشرفت های مورد انتظار LLM عبارتند از:
- بهره وری بهبود یافته: با LLM هایی که دارای صدها میلیون پارامتر هستند، به شدت به منابع نیاز دارند. با بهبود در سخت افزار و الگوریتم، آنها احتمالاً از نظر انرژی کارآمدتر می شوند. این همچنین زمان پاسخگویی را سریعتر می کند.
- آگاهی زمینه ای بهبود یافته: LLM ها خودآموز هستند. هرچه استفاده و بازخورد بیشتری دریافت کنند، بهتر می شوند. مهمتر از همه، این بدون هیچ گونه مهندسی عمده دیگری است. با پیشرفت تکنولوژی، این امر شاهد بهبود قابلیتهای زبانی و آگاهی زمینهای خواهد بود.
- آموزش دیده برای وظایف خاص: ابزارهای Jack-of-all-trade که چهره عمومی LLM ها هستند، مستعد خطا هستند. اما همانطور که توسعه می یابند و کاربران آنها را برای نیازهای خاص آموزش می دهند، LLM ها می توانند نقش بزرگی در زمینه هایی مانند پزشکی، حقوق، امور مالی و آموزش ایفا کنند.
- یکپارچگی بیشتر: LLM ها می توانند به دستیارهای دیجیتال شخصی تبدیل شوند. به سیری در مورد استروئیدها فکر کنید، و این ایده را دریافت خواهید کرد. LLM ها می توانند به دستیاران مجازی تبدیل شوند که در همه چیز از پیشنهاد غذا گرفته تا انجام مکاتبات به شما کمک می کنند.
اینها تنها تعدادی از مناطقی هستند که LLM احتمالاً بخش بزرگی از زندگی ما خواهند شد.
LLMs در حال تبدیل و آموزش
LLM ها در حال باز کردن دنیای هیجان انگیزی از امکانات هستند. ظهور سریع رباتهای چت مانند ChatGPT، Bing Chat و Google Bard شاهدی بر سرریز منابع در این زمینه است.
چنین افزایش منابع تنها می تواند این ابزارها را قوی تر، همه کاره تر و دقیق تر کند. کاربردهای بالقوه چنین ابزارهایی بسیار گسترده است، و در حال حاضر، ما فقط سطح یک منبع جدید باورنکردنی را خراش می دهیم.