اگر MapReduce مورد علاقه شما بوده است، اکنون زمان انتقال به خط لوله جمع آوری MongoDB برای مقابله با عملیات پیچیده است.
خط لوله تجمیع روش پیشنهادی برای اجرای پرس و جوهای پیچیده در MongoDB است. اگر از MapReduce MongoDB استفاده میکنید، بهتر است برای محاسبات کارآمدتر به خط لوله جمعآوری بروید.
Aggregation در MongoDB چیست و چگونه کار می کند؟
خط لوله تجمع یک فرآیند چند مرحله ای برای اجرای پرس و جوهای پیشرفته در MongoDB است. داده ها را از طریق مراحل مختلف پردازش می کند که خط لوله نامیده می شود. می توانید از نتایج تولید شده از یک سطح به عنوان الگوی عملیات در سطح دیگر استفاده کنید.
برای مثال، میتوانید نتیجه یک عملیات تطبیق را برای مرتبسازی به آن ترتیب به مرحله دیگری منتقل کنید تا زمانی که خروجی مورد نظر را به دست آورید.
هر مرحله از خط لوله تجمع دارای یک اپراتور MongoDB است و یک یا چند سند تبدیل شده را تولید می کند. بسته به درخواست شما، یک سطح می تواند چندین بار در خط لوله ظاهر شود. برای مثال، ممکن است لازم باشد از مراحل $count یا $sort بیش از یک بار در خط لوله تجمع استفاده کنید.
مراحل خط لوله تجمع
خط لوله تجمیع داده ها را در یک پرس و جو از چندین مرحله عبور می دهد. چندین مرحله وجود دارد و می توانید جزئیات آنها را در مستندات MongoDB بیابید.
بیایید برخی از پرکاربردترین آنها را در زیر تعریف کنیم.
مرحله $match
این مرحله به شما کمک می کند تا قبل از شروع سایر مراحل تجمیع، شرایط فیلترینگ خاص را تعریف کنید. میتوانید از آن برای انتخاب دادههای منطبق که میخواهید در خط لوله تجمع استفاده کنید، استفاده کنید.
مرحله گروه $
مرحله گروهی داده ها را بر اساس معیارهای خاص با استفاده از جفت های کلید-مقدار به گروه های مختلف جدا می کند. هر گروه یک کلید را در سند خروجی نشان می دهد.
به عنوان مثال، داده های نمونه فروش زیر را در نظر بگیرید:
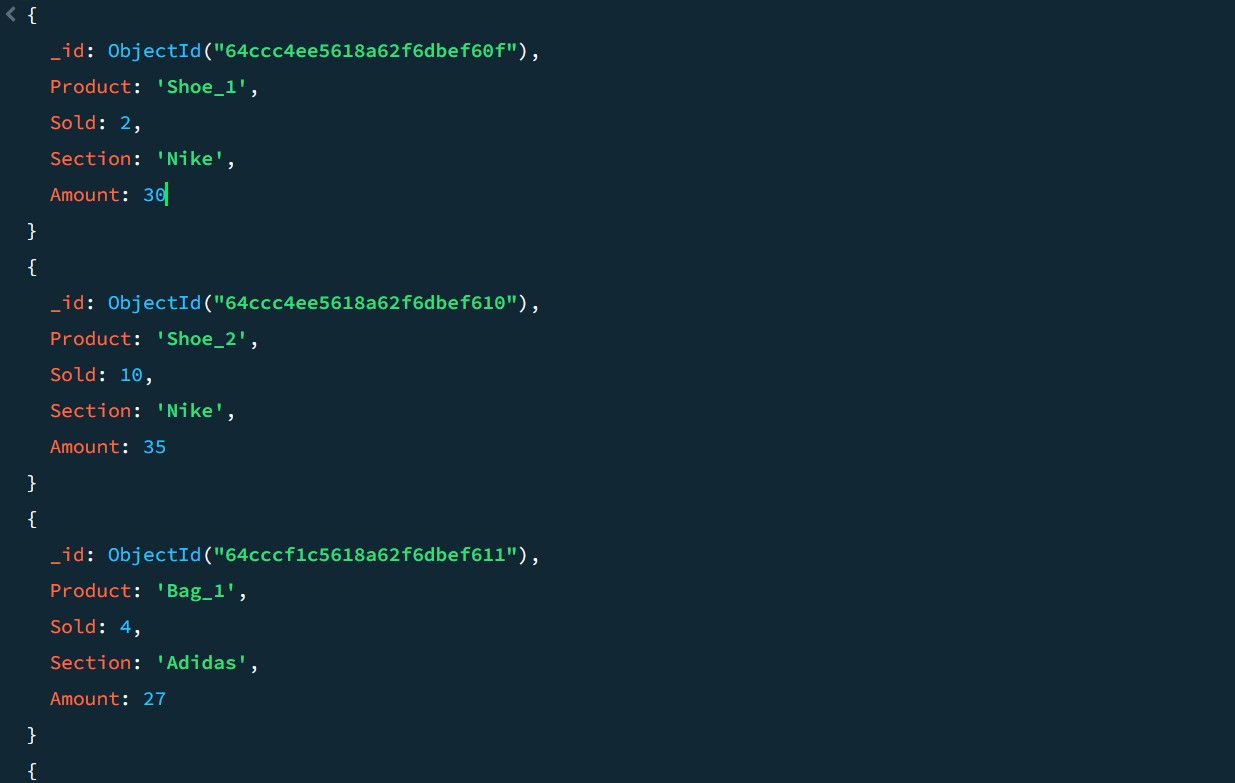
با استفاده از خط لوله تجمیع، می توانید تعداد کل فروش و فروش برتر را برای هر بخش محصول محاسبه کنید:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
جفت _id: $Section سند خروجی را بر اساس بخش ها گروه بندی می کند. با تعیین فیلدهای top_sales_count و top_sales، MongoDB کلیدهای تازه ای را بر اساس عملیات تعریف شده توسط جمع کننده ایجاد می کند. این می تواند $sum، $min، $max یا $avg باشد.
مرحله $skip
می توانید از مرحله $skip برای حذف تعداد مشخصی از اسناد در خروجی استفاده کنید. معمولا بعد از مرحله گروهی می آید. به عنوان مثال، اگر انتظار دارید دو سند خروجی داشته باشید اما یکی را نادیده بگیرید، تجمیع فقط سند دوم را خروجی می دهد.
برای افزودن مرحله پرش، عملیات $skip را در خط لوله تجمع وارد کنید:
...,
{
$skip: 1
},
مرحله مرتب سازی $
مرحله مرتب سازی به شما امکان می دهد داده ها را به ترتیب نزولی یا صعودی مرتب کنید. برای مثال، میتوانیم دادههای موجود در مثال پرس و جو قبلی را به ترتیب نزولی مرتب کنیم تا مشخص کنیم کدام بخش بیشترین فروش را دارد.
عملگر $sort را به کوئری قبلی اضافه کنید:
...,
{
$sort: {top_sales: -1}
},
مرحله $limit
عملیات حد به کاهش تعداد اسناد خروجی که می خواهید خط لوله تجمیع نشان دهد کمک می کند. به عنوان مثال، از عملگر $limit استفاده کنید تا قسمتی را که بیشترین فروش را در مرحله قبل دارد، دریافت کنید:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
موارد فوق فقط اولین سند را برمی گرداند. این بخش با بالاترین فروش است، زیرا در بالای خروجی مرتب شده ظاهر می شود.
مرحله پروژه $
مرحله $project به شما امکان می دهد تا سند خروجی را به دلخواه شکل دهید. با استفاده از عملگر $project، می توانید مشخص کنید که کدام فیلد در خروجی گنجانده شود و نام کلید آن را سفارشی کنید.
برای مثال، یک نمونه خروجی بدون مرحله $project به نظر می رسد:
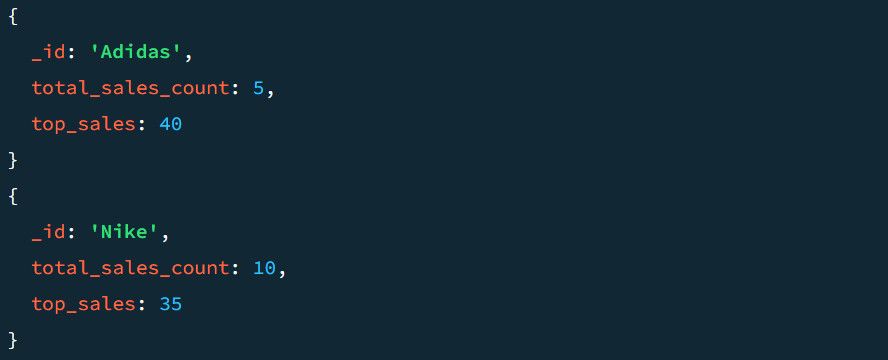
بیایید ببینیم که در مرحله $project چگونه به نظر می رسد. برای افزودن $project به خط لوله:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
از آنجایی که قبلاً داده ها را بر اساس بخش های محصول گروه بندی کرده ایم، موارد فوق شامل هر بخش محصول در سند خروجی می شود. همچنین تضمین می کند که تعداد فروش انبوه و فروش برتر در خروجی به عنوان TotalSold و TopSale مشخص می شود.
خروجی نهایی نسبت به قبلی بسیار تمیزتر است:

مرحله $unwind
مرحله $unwind یک آرایه در یک سند را به اسناد جداگانه تجزیه می کند. به عنوان مثال، داده های سفارشات زیر را در نظر بگیرید:
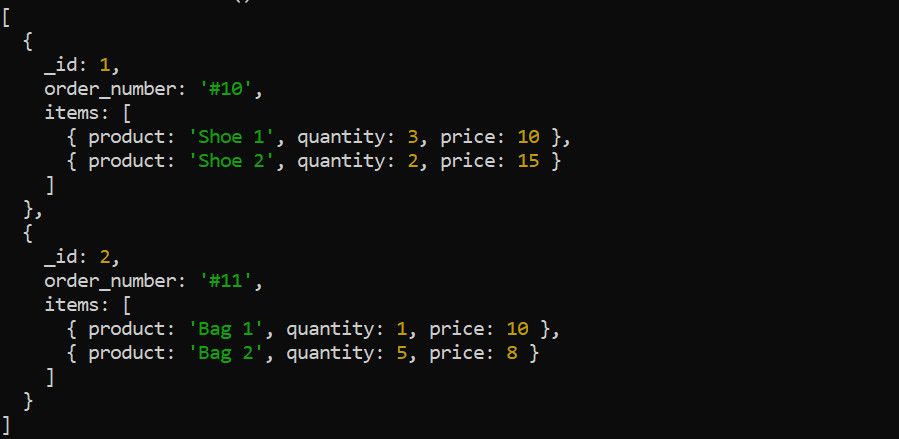
قبل از اعمال سایر مراحل تجمیع، از مرحله $unwind برای تجزیه آرایه آیتم ها استفاده کنید. برای مثال، اگر میخواهید کل درآمد را برای هر محصول محاسبه کنید، باز کردن آرایه اقلام منطقی است:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
در اینجا نتیجه جستجوی تجمع بالا آمده است:

نحوه ایجاد یک خط لوله تجمعی در MongoDB
در حالی که خط لوله تجمیع شامل چندین عملیات است، مراحل مشخص شده قبلی به شما ایده ای درباره نحوه اعمال آنها در خط لوله، از جمله پرس و جو اولیه برای هر یک، می دهد.
با استفاده از نمونه دادههای فروش قبلی، اجازه دهید برخی از مراحلی که در بالا مورد بحث قرار گرفتهاند را در یک قسمت برای دید وسیعتری از خط لوله تجمع داشته باشیم:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
خروجی نهایی شبیه چیزی است که قبلاً دیده اید:
خط لوله تجمع در مقابل MapReduce
تا قبل از منسوخ شدن آن از MongoDB 5.0، روش متعارف جمع آوری داده ها در MongoDB از طریق MapReduce بود. اگرچه MapReduce کاربردهای گسترده تری فراتر از MongoDB دارد، اما نسبت به خط لوله تجمیع کارایی کمتری دارد و برای نوشتن نقشه و کاهش عملکردها به طور جداگانه نیاز به برنامه نویسی شخص ثالث دارد.
از طرف دیگر خط لوله تجمع فقط مختص MongoDB است. اما روشی تمیزتر و کارآمدتر برای اجرای پرس و جوهای پیچیده ارائه می دهد. علاوه بر سادگی و مقیاس پذیری پرس و جو، مراحل خط لوله مشخص شده، خروجی را قابل تنظیم تر می کند.
تفاوت های بسیار بیشتری بین خط لوله تجمع و MapReduce وجود دارد. هنگام جابجایی از MapReduce به خط لوله تجمع، آنها را خواهید دید.
پرس و جوهای کلان داده را در MongoDB کارآمد کنید
اگر میخواهید محاسبات عمیق را روی دادههای پیچیده در MongoDB انجام دهید، درخواست شما باید تا حد امکان کارآمد باشد. خط لوله تجمیع برای پرس و جوی پیشرفته ایده آل است. به جای دستکاری داده ها در عملیات جداگانه، که اغلب عملکرد را کاهش می دهد، تجمیع به شما این امکان را می دهد که همه آنها را در یک خط لوله عملکرد واحد بسته بندی کنید و یک بار آنها را اجرا کنید.
در حالی که خط لوله جمعآوری کارآمدتر از MapReduce است، میتوانید با فهرست کردن دادههای خود تجمیع را سریعتر و کارآمدتر کنید. این مقدار دادههایی را که MongoDB برای اسکن در هر مرحله جمعآوری نیاز دارد، محدود میکند.