
متا Llama 2 را در تابستان 2023 منتشر کرد. نسخه جدید Llama با 40٪ توکن های بیشتری نسبت به مدل اصلی Llama تنظیم شده است که طول زمینه آن را دو برابر کرده و به طور قابل توجهی از سایر مدل های منبع باز موجود بهتر است. سریع ترین و ساده ترین راه برای دسترسی به Llama 2 از طریق یک API از طریق یک پلت فرم آنلاین است. با این حال، اگر می خواهید بهترین تجربه را داشته باشید، نصب و بارگذاری Llama 2 به طور مستقیم بر روی رایانه شما بهترین است.
متا Llama 2 را در تابستان 2023 منتشر کرد. نسخه جدید Llama با 40٪ توکن های بیشتری نسبت به مدل اصلی Llama تنظیم شده است که طول زمینه آن را دو برابر کرده و به طور قابل توجهی از سایر مدل های منبع باز موجود بهتر است. سریع ترین و ساده ترین راه برای دسترسی به Llama 2 از طریق یک API از طریق یک پلت فرم آنلاین است. با این حال، اگر می خواهید بهترین تجربه را داشته باشید، نصب و بارگذاری Llama 2 به طور مستقیم بر روی رایانه شما بهترین است.
با در نظر گرفتن این موضوع، ما یک راهنمای گام به گام در مورد نحوه استفاده از Text-Generation-WebUI برای بارگذاری یک Llama 2 LLM کوانتیزه شده به صورت محلی در رایانه خود ایجاد کرده ایم.
چرا Llama 2 را به صورت محلی نصب کنید؟
دلایل زیادی وجود دارد که چرا مردم لاما 2 را مستقیماً اجرا می کنند. برخی برای نگرانی های حفظ حریم خصوصی، برخی برای سفارشی سازی و برخی دیگر برای قابلیت های آفلاین این کار را انجام می دهند. اگر در حال تحقیق، تنظیم دقیق یا یکپارچه سازی Llama 2 برای پروژه های خود هستید، پس دسترسی به Llama 2 از طریق API ممکن است برای شما مناسب نباشد. هدف از اجرای LLM به صورت محلی بر روی رایانه شخصی شما کاهش اتکا به ابزارهای هوش مصنوعی شخص ثالث و استفاده از هوش مصنوعی در هر زمان و هر مکان است، بدون نگرانی در مورد نشت داده های بالقوه حساس به شرکت ها و سازمان های دیگر.
با این گفته، اجازه دهید با راهنمای گام به گام نصب Llama 2 به صورت محلی شروع کنیم.
مرحله 1: Visual Studio 2019 Build Tool را نصب کنید
برای ساده کردن کارها، از یک نصب کننده با یک کلیک برای Text-Generation-WebUI (برنامه ای که برای بارگیری Llama 2 با رابط کاربری گرافیکی استفاده می شود) استفاده می کنیم. با این حال، برای اینکه این نصب کننده کار کند، باید ابزار ساخت Visual Studio 2019 را دانلود کرده و منابع لازم را نصب کنید.
دانلود: Visual Studio 2019 (رایگان)
- ادامه دهید و نسخه جامعه نرم افزار را دانلود کنید.
- حالا Visual Studio 2019 را نصب کنید، سپس نرم افزار را باز کنید. پس از باز شدن، کادر توسعه دسکتاپ با C++ را علامت بزنید و install را بزنید.
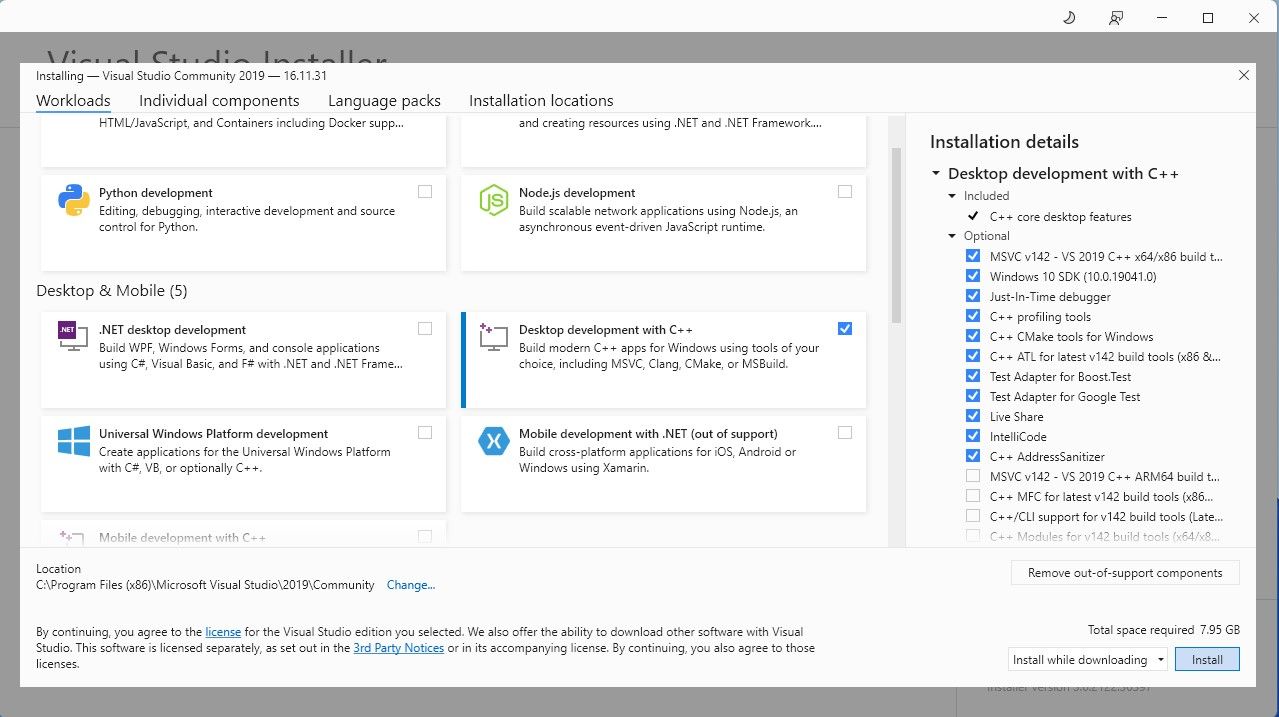
اکنون که توسعه دسکتاپ را با C++ نصب کرده اید، زمان آن رسیده است که نصب کننده Text-Generation-WebUI را با یک کلیک دانلود کنید.
مرحله 2: Text-Generation-WebUI را نصب کنید
نصبکننده تککلیک Text-Generation-WebUI اسکریپتی است که بهطور خودکار پوشههای مورد نیاز را ایجاد میکند و محیط Conda و همه الزامات لازم برای اجرای یک مدل هوش مصنوعی را تنظیم میکند.
برای نصب اسکریپت، نصب کننده را با یک کلیک با کلیک روی Code > Download ZIP دانلود کنید.
دانلود:Text-Generation-WebUI Installer (رایگان)
- پس از دانلود، فایل ZIP را در مکان دلخواه خود استخراج کنید، سپس پوشه استخراج شده را باز کنید.
- در داخل پوشه، به پایین بروید و به دنبال برنامه شروع مناسب برای سیستم عامل خود بگردید. با دوبار کلیک کردن روی اسکریپت مناسب برنامه ها را اجرا کنید. اگر در ویندوز هستید، start_windows batch file را برای MacOS، start_macos shell scrip را برای Linux، start_linux shell script را انتخاب کنید.
- آنتی ویروس شما ممکن است یک هشدار ایجاد کند. این خوب است درخواست فقط یک آنتی ویروس مثبت کاذب برای اجرای یک فایل دسته ای یا اسکریپت است. به هر حال روی Run کلیک کنید.
- یک ترمینال باز می شود و راه اندازی را شروع می کند. در اوایل، راهاندازی متوقف میشود و از شما میپرسد از چه پردازنده گرافیکی استفاده میکنید. نوع مناسب GPU نصب شده بر روی کامپیوتر خود را انتخاب کرده و اینتر را بزنید. برای کسانی که کارت گرافیک اختصاصی ندارند، None را انتخاب کنید (من می خواهم مدل ها را در حالت CPU اجرا کنم). به خاطر داشته باشید که اجرای در حالت CPU در مقایسه با اجرای مدل با یک GPU اختصاصی بسیار کندتر است.
- پس از تکمیل تنظیمات، اکنون می توانید Text-Generation-WebUI را به صورت محلی راه اندازی کنید. می توانید این کار را با باز کردن مرورگر وب دلخواه خود و وارد کردن آدرس IP ارائه شده در URL انجام دهید.
- WebUI اکنون برای استفاده آماده است.
- اگر در ویندوز هستید، start_windows batch file را انتخاب کنید
- برای MacOS، اسکریپت پوسته macos startup را انتخاب کنید
- برای لینوکس، اسکریپت پوسته start_linux.
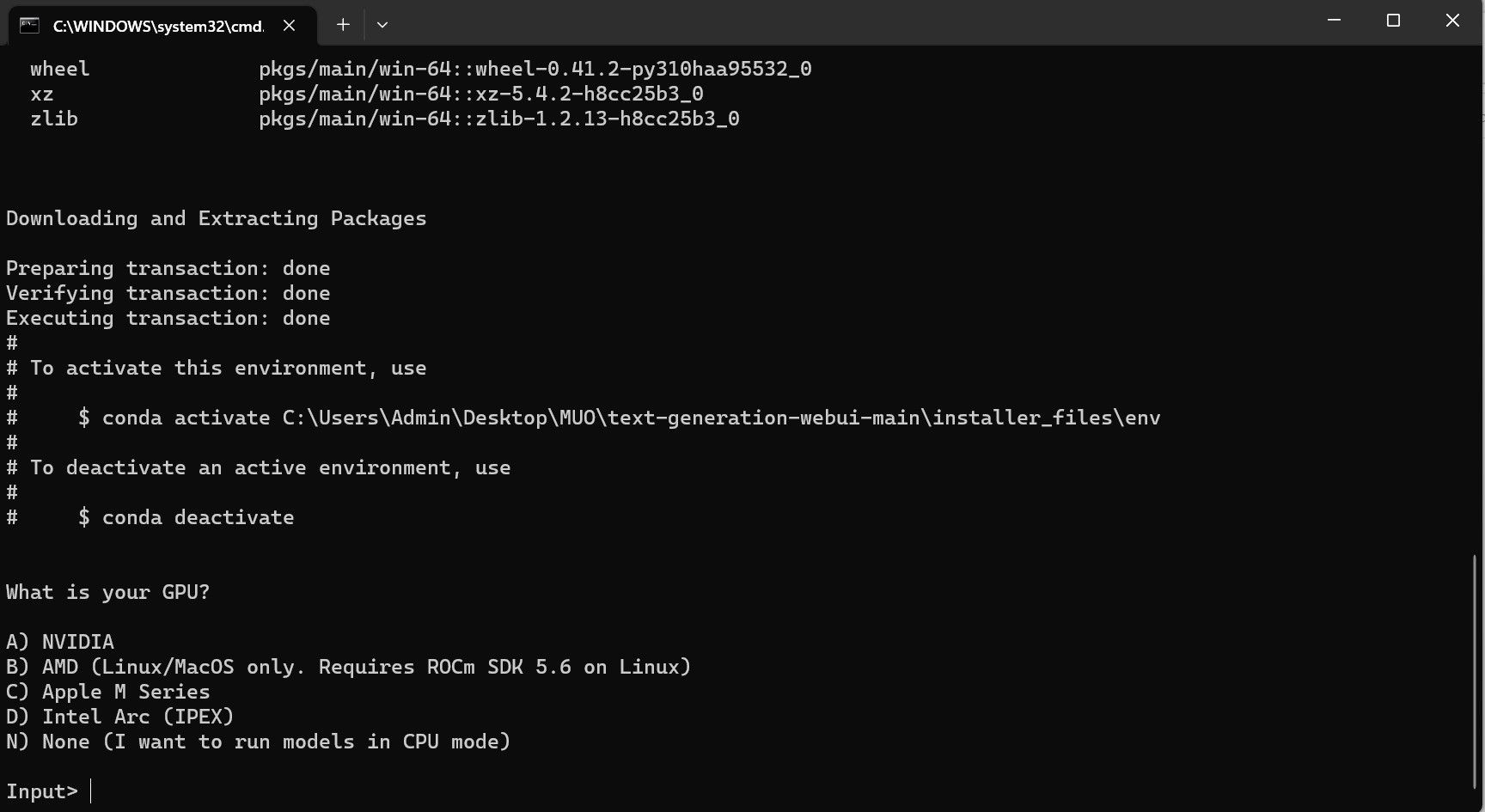
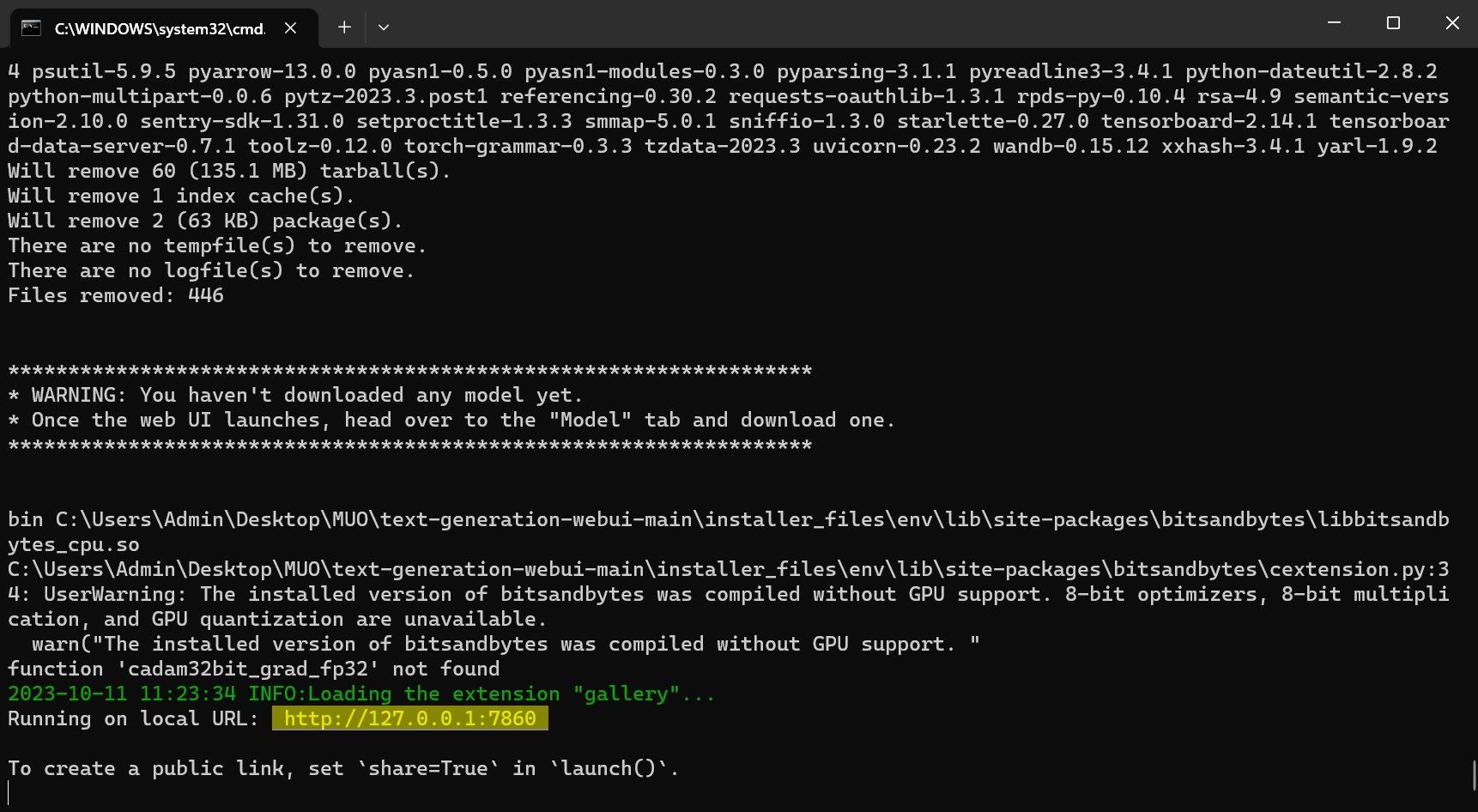
با این حال، برنامه فقط یک مدل لودر است. بیایید Llama 2 را برای لودر مدل دانلود کنیم تا راه اندازی شود.
مرحله 3: مدل Llama 2 را دانلود کنید
هنگام تصمیم گیری در مورد اینکه به کدام تکرار از Llama 2 نیاز دارید، موارد زیادی وجود دارد که باید در نظر بگیرید. اینها شامل پارامترها، کوانتیزاسیون، بهینه سازی سخت افزار، اندازه و استفاده است. تمام این اطلاعات در نام مدل مشخص می شود.
- پارامترها: تعداد پارامترهای مورد استفاده برای آموزش مدل. پارامترهای بزرگتر مدلهای توانمندتری را میسازند اما به قیمت کارایی.
- استفاده: می تواند استاندارد یا چت باشد. یک مدل چت برای استفاده به عنوان یک ربات چت مانند ChatGPT بهینه شده است، در حالی که استاندارد مدل پیش فرض است.
- بهینه سازی سخت افزار: به این اشاره دارد که چه سخت افزاری مدل را به بهترین شکل اجرا می کند. GPTQ به این معنی است که مدل برای اجرا بر روی یک GPU اختصاصی بهینه شده است، در حالی که GGML برای اجرا بر روی یک CPU بهینه شده است.
- کوانتیزاسیون: نشان دهنده دقت وزن ها و فعال سازی ها در یک مدل است. برای استنتاج، دقت q4 بهینه است.
- اندازه: به اندازه مدل خاص اشاره دارد.
توجه داشته باشید که برخی از مدلها ممکن است متفاوت چیده شوند و حتی ممکن است اطلاعات یکسانی نمایش داده نشوند. با این حال، این نوع قرارداد نامگذاری در کتابخانه مدل HuggingFace نسبتاً رایج است، بنابراین هنوز ارزش درک آن را دارد.

در این مثال، مدل را می توان به عنوان یک مدل Llama 2 با اندازه متوسط شناسایی کرد که بر روی 13 میلیارد پارامتر بهینه شده برای استنتاج چت با استفاده از یک CPU اختصاصی آموزش دیده است.
برای کسانی که روی یک GPU اختصاصی کار می کنند، یک مدل GPTQ را انتخاب کنید، در حالی که برای کسانی که از CPU استفاده می کنند، GGML را انتخاب کنید. اگر میخواهید مانند ChatGPT با مدل چت کنید، چت را انتخاب کنید، اما اگر میخواهید مدل را با قابلیتهای کامل آن آزمایش کنید، از مدل استاندارد استفاده کنید. در مورد پارامترها، بدانید که استفاده از مدل های بزرگتر نتایج بهتری را به قیمت عملکرد ارائه می دهد. من شخصاً توصیه می کنم با یک مدل 7B شروع کنید. در مورد کوانتیزاسیون، از q4 استفاده کنید، زیرا فقط برای استنتاج است.
دانلود:GGML (رایگان)
دانلود:GPTQ (رایگان)
اکنون که می دانید به چه تکراری از Llama 2 نیاز دارید، ادامه دهید و مدل مورد نظر خود را دانلود کنید.
در مورد من، از آنجایی که من این را روی یک اولترابوک اجرا می کنم، از یک مدل GGML که برای چت تنظیم شده است، llama-2-7b-chat-ggmlv3.q4_K_S.bin استفاده خواهم کرد.
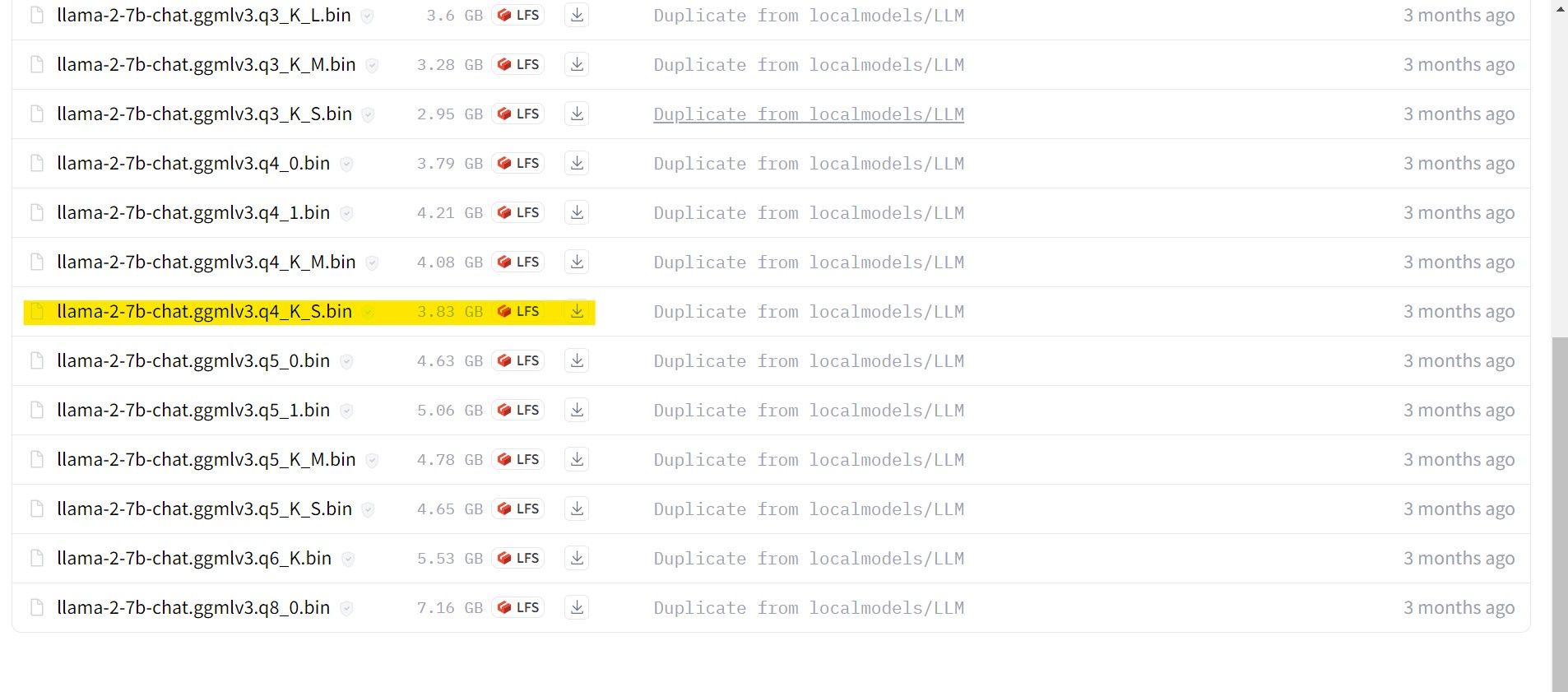
پس از پایان دانلود، مدل را در text-generation-webui-main > models قرار دهید.
اکنون که مدل خود را دانلود کرده اید و در پوشه مدل قرار داده اید، نوبت به پیکربندی مدل لودر می رسد.
مرحله 4: پیکربندی Text-Generation-WebUI
حالا بیایید مرحله پیکربندی را شروع کنیم.
- یک بار دیگر، Text-Generation-WebUI را با اجرای فایل start_(سیستم عامل خود) باز کنید (مراحل قبلی را در بالا ببینید).
- در برگه های واقع در بالای رابط کاربری گرافیکی، روی Model کلیک کنید. روی دکمه refresh در منوی کشویی مدل کلیک کنید و مدل خود را انتخاب کنید.
- اکنون روی منوی کشویی Model loader کلیک کنید و AutoGPTQ را برای کسانی که از مدل GTPQ استفاده می کنند و ctransformers را برای کسانی که از مدل GGML استفاده می کنند انتخاب کنید. در نهایت بر روی Load کلیک کنید تا مدل شما بارگذاری شود.
- برای استفاده از مدل، تب Chat را باز کرده و شروع به تست مدل کنید.
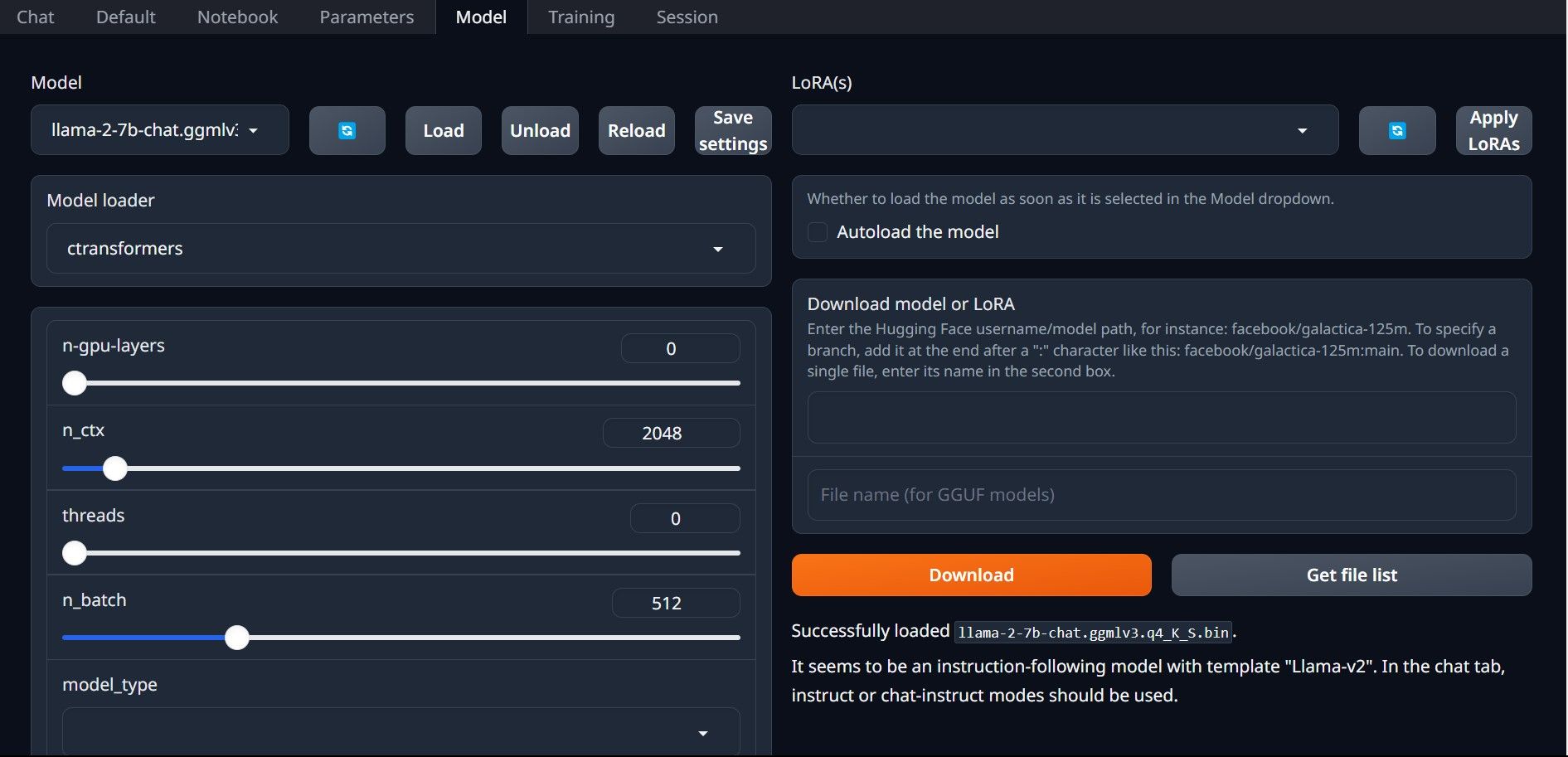
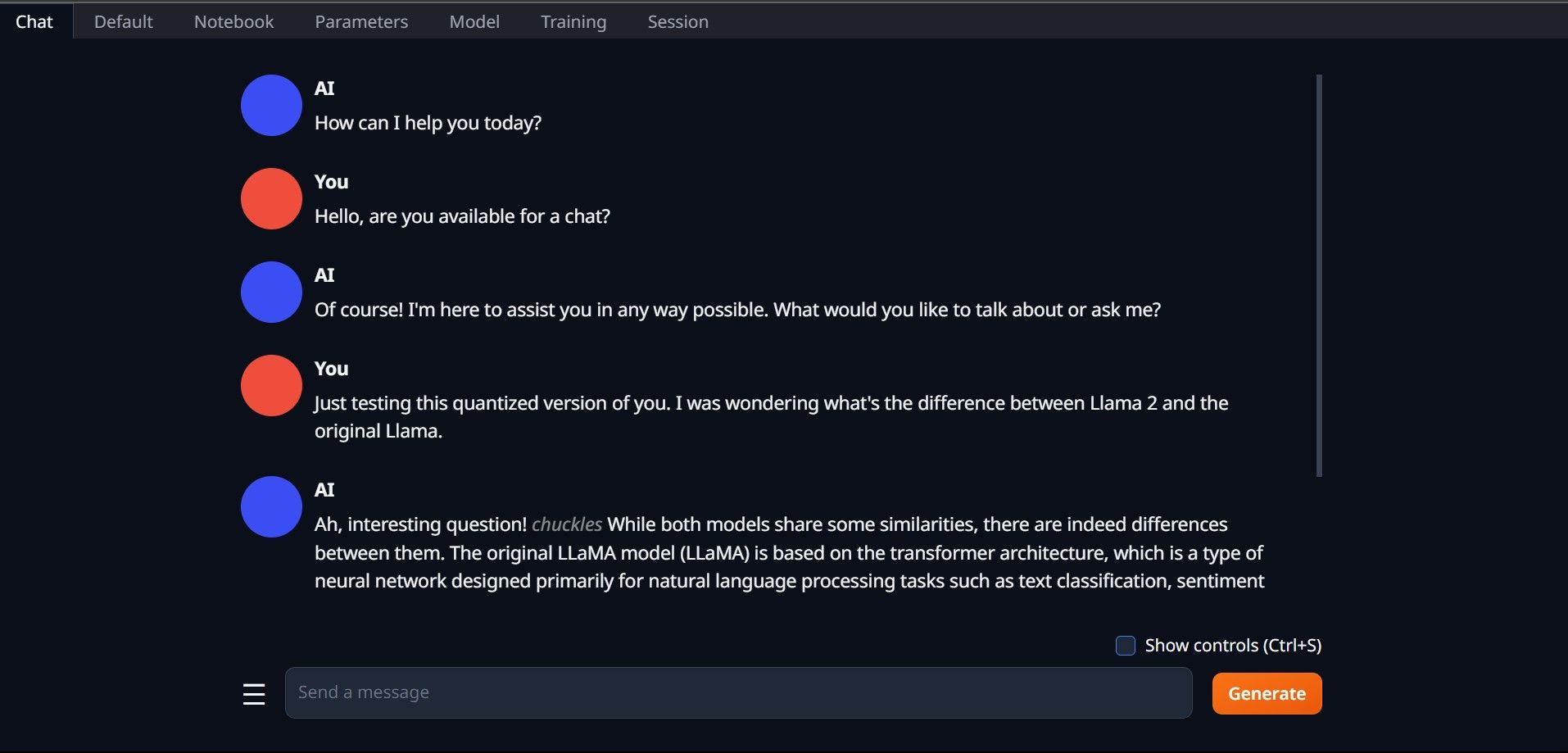
تبریک میگوییم، Llama2 را با موفقیت در رایانه محلی خود بارگیری کردید!
سایر LLM ها را امتحان کنید
اکنون که می دانید چگونه Llama 2 را مستقیماً با استفاده از Text-Generation-WebUI بر روی رایانه خود اجرا کنید، باید بتوانید سایر LLM ها را به غیر از Llama نیز اجرا کنید. فقط قوانین نامگذاری مدل ها را به یاد داشته باشید و اینکه فقط نسخه های کوانتیزه شده مدل ها (معمولاً دقت q4) را می توان بر روی رایانه های شخصی معمولی بارگذاری کرد. بسیاری از LLM های کوانتیزه شده در HuggingFace در دسترس هستند. اگر میخواهید مدلهای دیگر را کاوش کنید، TheBloke را در کتابخانه مدل HuggingFace جستجو کنید، و باید مدلهای زیادی را در دسترس پیدا کنید.