
ابزار جستجوگر کپی خود را بسازید و با قابلیت های قدرتمند ماژول Difflib آشنا شوید.
با افزایش محبوبیت محتوای دیجیتال، محافظت از آن در برابر کپی کردن و استفاده نادرست از همیشه مهمتر شده است. ابزار تشخیص سرقت ادبی می تواند به معلمان کمک کند تا کار دانش آموزان را ارزیابی کنند، مؤسسات مقالات تحقیقاتی را بررسی کنند، و نویسندگان سرقت دارایی معنوی آنها را تشخیص دهند.
ساختن یک ابزار سرقت ادبی می تواند به شما در درک تطبیق توالی، عملیات فایل و رابط کاربری کمک کند. همچنین تکنیکهای پردازش زبان طبیعی (NLP) را برای ارتقای برنامه خود بررسی خواهید کرد.
ماژول Tkinter و Difflib
برای ساخت آشکارساز سرقت ادبی، از Tkinter و ماژول Difflib استفاده خواهید کرد. Tkinter یک کتابخانه ساده و چند پلتفرمی است که می توانید از آن برای ایجاد سریع رابط کاربری گرافیکی استفاده کنید.
ماژول Difflib بخشی از کتابخانه استاندارد پایتون است که کلاس ها و توابعی را برای مقایسه دنباله هایی مانند رشته ها، لیست ها و فایل ها ارائه می دهد. با آن می توانید برنامه هایی مانند تصحیح خودکار متن، سیستم کنترل نسخه ساده شده یا ابزار خلاصه سازی متن بسازید.
چگونه با استفاده از پایتون یک آشکارساز سرقت ادبی بسازیم
شما می توانید کل کد منبع ساخت یک آشکارساز سرقت ادبی را با استفاده از پایتون در این مخزن GitHub پیدا کنید.
ماژول های مورد نیاز را وارد کنید. یک متد تعریف کنید، load_file_or_display_contents() که ورودی و text_widget را به عنوان آرگومان می گیرد. این روش یک فایل متنی را بارگذاری می کند و محتویات آن را در یک ویجت متنی نمایش می دهد.
از متد get() برای استخراج مسیر فایل استفاده کنید. اگر کاربر چیزی وارد نکرده است، از متد askopenfilename() برای باز کردن پنجره گفتگوی فایل استفاده کنید تا فایل مورد نظر را برای بررسی سرقت ادبی انتخاب کنید. اگر کاربر مسیر فایل را انتخاب کرد، ورودی قبلی را در صورت وجود از ابتدا تا انتها پاک کنید و مسیری را که انتخاب کرده است وارد کنید.
import tkinter as tk
from tkinter import filedialog
from difflib import SequenceMatcher
def load_file_or_display_contents(entry, text_widget):
file_path = entry.get()
if not file_path:
file_path = filedialog.askopenfilename()
if file_path:
entry.delete(0, tk.END)
entry.insert(tk.END, file_path)
فایل را در حالت خواندن باز کنید و محتویات را در متغیر متن ذخیره کنید. محتویات text_widget را پاک کنید و متنی را که قبلا استخراج کرده اید وارد کنید.
with open(file_path, 'r') as file:
text = file.read()
text_widget.delete(1.0, tk.END)
text_widget.insert(tk.END, text)
یک متد به نام compare_text() تعریف کنید که از آن برای مقایسه دو تکه متن و محاسبه درصد شباهت آنها استفاده می کنید. از کلاس SequenceMatcher() Difflib برای مقایسه توالی ها و تعیین شباهت استفاده کنید. تابع مقایسه سفارشی را روی None تنظیم کنید تا از مقایسه پیشفرض استفاده کنید و متنی را که میخواهید مقایسه کنید ارسال کنید.
از روش نسبت برای بدست آوردن شباهت در قالب ممیز شناور استفاده کنید که می توانید برای محاسبه درصد شباهت استفاده کنید. از متد get_opcodes() برای بازیابی مجموعهای از عملیات استفاده کنید که میتوانید از آنها برای برجسته کردن قسمتهای مشابه متن و برگرداندن آن به همراه درصد شباهت استفاده کنید.
def compare_text(text1, text2):
d = SequenceMatcher(None, text1, text2)
similarity_ratio = d.ratio()
similarity_percentage = int(similarity_ratio * 100)
diff = list(d.get_opcodes())
return similarity_percentage, diff
یک متد تعریف کنید show_similarity(). از متد get() برای استخراج متن از هر دو جعبه متن و ارسال آنها به تابع ()compare_text استفاده کنید. محتویات کادر متنی که نتیجه را نمایش می دهد پاک کنید و درصد شباهت را درج کنید. برچسب “همان” را از هایلایت قبلی (در صورت وجود) حذف کنید.
def show_similarity():
text1 = text_textbox1.get(1.0, tk.END)
text2 = text_textbox2.get(1.0, tk.END)
similarity_percentage, diff = compare_text(text1, text2)
text_textbox_diff.delete(1.0, tk.END)
text_textbox_diff.insert(tk.END, f"Similarity: {similarity_percentage}%")
text_textbox1.tag_remove("same", "1.0", tk.END)
text_textbox2.tag_remove("same", "1.0", tk.END)
متد get_opcode() پنج تاپل را برمی گرداند: رشته opcode، شاخص شروع دنباله اول، شاخص پایان دنباله اول، شاخص شروع دنباله دوم، و اندیس پایان دنباله دوم.
رشته opcode می تواند یکی از چهار مقدار ممکن باشد: جایگزین، حذف، درج و برابر. زمانی جایگزین میشوید که بخشی از متن در هر دو دنباله متفاوت باشد، و شخصی یک قسمت را با قسمت دیگر جایگزین کند. هنگامی که بخشی از متن در دنباله اول وجود داشته باشد اما در قسمت دوم وجود نداشته باشد، حذف خواهید شد.
هنگامی که بخشی از متن در سکانس اول وجود ندارد اما در سکانس دوم وجود دارد، درج دریافت می کنید. وقتی قسمت های متن یکسان باشد، برابر می شوید. تمام این مقادیر را در متغیرهای مناسب ذخیره کنید. اگر رشته opcode برابر است، همان تگ را به دنباله متن اضافه کنید.
for opcode in diff:
tag = opcode[0]
start1 = opcode[1]
end1 = opcode[2]
start2 = opcode[3]
end2 = opcode[4]
if tag == "equal":
text_textbox1.tag_add("same", f"1.0+{start1}c", f"1.0+{end1}c")
text_textbox2.tag_add("same", f"1.0+{start2}c", f"1.0+{end2}c")
پنجره ریشه Tkinter را راه اندازی کنید. عنوان پنجره را تنظیم کنید و یک قاب در داخل آن تعریف کنید. قاب را با بالشتک مناسب در هر دو جهت سازماندهی کنید. دو برچسب برای نمایش متن 1 و متن 2 تعریف کنید. عنصر والد را که باید در آن قرار گیرد و متنی که باید نمایش داده شود را تنظیم کنید.
سه جعبه متن تعریف کنید، دو تا برای متن هایی که می خواهید مقایسه کنید و یکی برای نمایش نتیجه. عنصر والد، عرض و ارتفاع را اعلام کنید و گزینه wrap را روی tk.WORD قرار دهید تا مطمئن شوید که برنامه کلمات را در نزدیکترین مرز قرار می دهد و هیچ کلمه ای را در بین نمی شکند.
root = tk.Tk()
root.title("Text Comparison Tool")
frame = tk.Frame(root)
frame.pack(padx=10, pady=10)
text_label1 = tk.Label(frame, text="Text 1:")
text_label1.grid(row=0, column=0, padx=5, pady=5)
text_textbox1 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)
text_textbox1.grid(row=0, column=1, padx=5, pady=5)
text_label2 = tk.Label(frame, text="Text 2:")
text_label2.grid(row=0, column=2, padx=5, pady=5)
text_textbox2 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)
text_textbox2.grid(row=0, column=3, padx=5, pady=5)
سه دکمه تعریف کنید، دو دکمه برای بارگذاری فایل ها و یکی برای مقایسه. عنصر والد، متنی که باید نمایش داده شود و عملکردی که باید با کلیک روی آن اجرا شود را تعریف کنید. دو ویجت ورودی ایجاد کنید تا مسیر فایل را وارد کنید و عنصر والد را به همراه عرض آن تعریف کنید.
با استفاده از Grid Manager همه این عناصر را در ردیف ها و ستون ها سازماندهی کنید. از pack برای سازماندهی compare_button و text_textbox_diff استفاده کنید. در صورت لزوم بالشتک مناسب اضافه کنید.
file_entry1 = tk.Entry(frame, width=50)
file_entry1.grid(row=1, column=2, columnspan=2, padx=5, pady=5)
load_button1 = tk.Button(frame, text="Load File 1", command=lambda: load_file_or_display_contents(file_entry1, text_textbox1))
load_button1.grid(row=1, column=0, padx=5, pady=5, columnspan=2)
file_entry2 = tk.Entry(frame, width=50)
file_entry2.grid(row=2, column=2, columnspan=2, padx=5, pady=5)
load_button2 = tk.Button(frame, text="Load File 2", command=lambda: load_file_or_display_contents(file_entry2, text_textbox2))
load_button2.grid(row=2, column=0, padx=5, pady=5, columnspan=2)
compare_button = tk.Button(root, text="Compare", command=show_similarity)
compare_button.pack(pady=5)
text_textbox_diff = tk.Text(root, wrap=tk.WORD, width=80, height=1)
text_textbox_diff.pack(padx=10, pady=10)
متنی که با پسزمینه زرد و رنگ فونت قرمز مشخص شده است را برجسته کنید.
text_textbox1.tag_configure("same", foreground="red", background="lightyellow")
text_textbox2.tag_configure("same", foreground="red", background="lightyellow")
تابع mainloop() به پایتون می گوید که حلقه رویداد Tkinter را اجرا کند و تا زمانی که پنجره را ببندید به رویدادها گوش دهد.
root.mainloop()
همه را کنار هم بگذارید و کد را برای تشخیص سرقت ادبی اجرا کنید.
نمونه خروجی آشکارساز سرقت ادبی
وقتی برنامه را اجرا می کنید، یک پنجره نمایش داده می شود. با زدن دکمه Load File 1، یک گفتگوی فایل باز می شود و از شما می خواهد که یک فایل را انتخاب کنید. با انتخاب یک فایل، برنامه محتویات داخل جعبه متن اول را نمایش می دهد. با ورود به مسیر و زدن Load File 2، برنامه محتویات را در کادر متن دوم نمایش می دهد. با زدن دکمه مقایسه، شباهت 100٪ را دریافت می کنید و کل متن را برای 100٪ شباهت برجسته می کند.
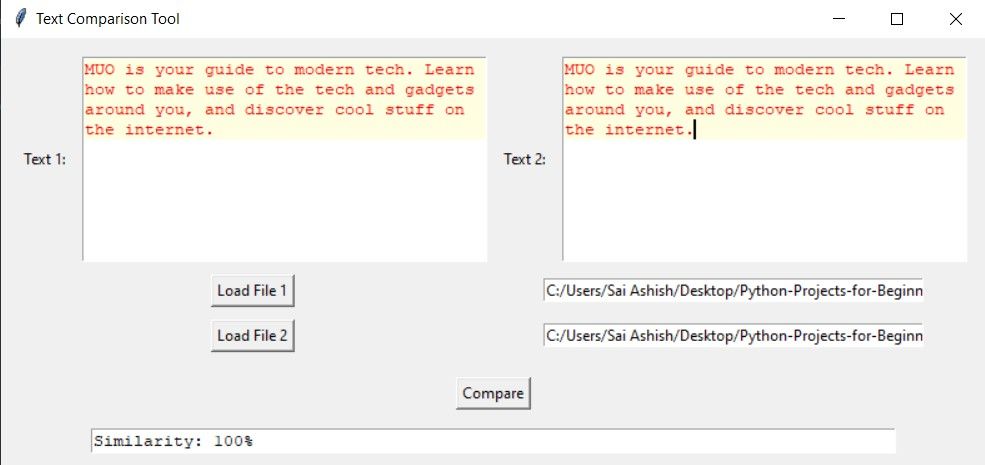
اگر خط دیگری را به یکی از جعبه های متن اضافه کنید و Compare را بزنید، برنامه قسمت مشابه را برجسته می کند و بقیه را کنار می گذارد.
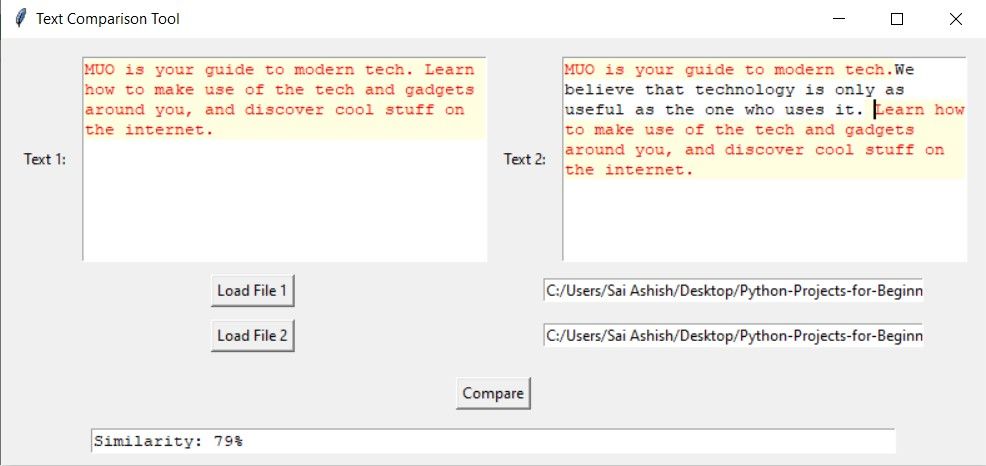
اگر شباهت کمی وجود داشته باشد، برنامه برخی از حروف یا کلمات را برجسته می کند، اما درصد شباهت بسیار کم است.
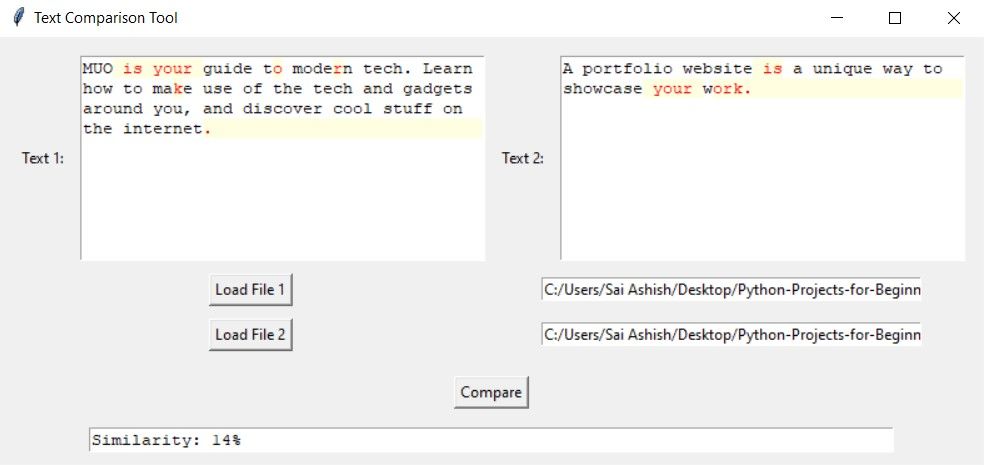
استفاده از NLP برای تشخیص سرقت ادبی
در حالی که Difflib یک روش قدرتمند برای مقایسه متن است، اما به تغییرات جزئی حساس است، درک زمینه محدودی دارد و اغلب برای متون بزرگ بی اثر است. شما باید پردازش زبان طبیعی را بررسی کنید زیرا می تواند تجزیه و تحلیل معنایی متن را انجام دهد، ویژگی های معنی دار را استخراج کند و درک زمینه ای داشته باشد.
علاوه بر این، می توانید مدل خود را برای زبان های مختلف آموزش دهید و آن را برای کارایی بهینه کنید. تعدادی از تکنیکهایی که میتوانید برای تشخیص سرقت ادبی استفاده کنید عبارتند از: شباهت جاکارد، شباهت کسینوس، جاسازی کلمات، تحلیل توالی پنهان و مدلهای دنباله به دنباله.