
از Llama 2 LLM منبع باز استفاده کنید تا یک چت بات سفارشی با پایتون بسازید.
Llama 2 یک مدل زبان بزرگ منبع باز (LLM) است که توسط Meta توسعه یافته است. این یک مدل زبان بزرگ منبع باز مناسب است که مسلماً بهتر از برخی از مدل های بسته مانند GPT-3.5 و PalM 2 است. از سه اندازه مدل متن تولیدی از پیش آموزش دیده و تنظیم شده تشکیل شده است که شامل 7 میلیارد، 13 میلیارد، و مدل های پارامتری 70 میلیاردی
با ساخت ربات چت با استفاده از Streamlit و Llama 2، قابلیتهای مکالمه Llama 2 را کشف خواهید کرد.
درک لاما 2: ویژگی ها و مزایا
Llama 2 چقدر با مدل قبلی خود Llama 1 متفاوت است؟
- اندازه مدل بزرگتر: مدل بزرگتر است و حداکثر 70 میلیارد پارامتر دارد. این به آن امکان می دهد تا ارتباطات پیچیده تری بین کلمات و جملات را بیاموزد.
- تواناییهای مکالمه بهبود یافته: یادگیری تقویتی از بازخورد انسانی (RLHF) تواناییهای برنامه مکالمه را بهبود میبخشد. این به مدل اجازه میدهد تا محتوای انسانی را حتی در تعاملات پیچیده تولید کند.
- استنتاج سریعتر: روش جدیدی به نام توجه پرس و جو گروهی را برای تسریع استنتاج معرفی می کند. این منجر به توانایی آن در ساخت برنامه های کاربردی مفیدتر مانند چت بات ها و دستیاران مجازی می شود.
- کارآمدتر: حافظه و منابع محاسباتی کارآمدتر از نسخه قبلی خود است.
- مجوز منبع باز و غیر تجاری: متن باز است. محققان و توسعه دهندگان می توانند از Llama 2 بدون محدودیت استفاده و اصلاح کنند.
Llama 2 به طور قابل توجهی از همه جهات از نسخه قبلی خود بهتر عمل می کند. این ویژگیها آن را به ابزاری قدرتمند برای بسیاری از برنامهها، مانند رباتهای گفتگو، دستیاران مجازی و درک زبان طبیعی تبدیل میکند.
راه اندازی یک محیط روشن برای توسعه چت بات
برای شروع ساخت اپلیکیشن خود، باید یک محیط توسعه راه اندازی کنید. این برای جداسازی پروژه شما از پروژه های موجود در دستگاه شما است.
ابتدا با ایجاد یک محیط مجازی با استفاده از کتابخانه Pipenv به صورت زیر شروع کنید:
pipenv shell
در مرحله بعد، کتابخانه های لازم برای ساخت ربات چت را نصب کنید.
pipenv install streamlit replicate
Streamlit: این یک چارچوب برنامه وب منبع باز است که یادگیری ماشین و برنامه های علم داده را به سرعت ارائه می کند.
Replicate: این یک پلتفرم ابری است که دسترسی به مدل های بزرگ منبع باز یادگیری ماشینی را برای استقرار فراهم می کند.
توکن API Llama 2 خود را از Replicate دریافت کنید
برای دریافت کلید رمز Replicate، ابتدا باید با استفاده از حساب GitHub خود یک حساب در Replicate ثبت کنید.
Replicate فقط اجازه ورود از طریق حساب GitHub را می دهد.
هنگامی که به داشبورد دسترسی پیدا کردید، به دکمه کاوش بروید و چت Llama 2 را جستجو کنید تا مدل llama-2–70b-chat را ببینید.
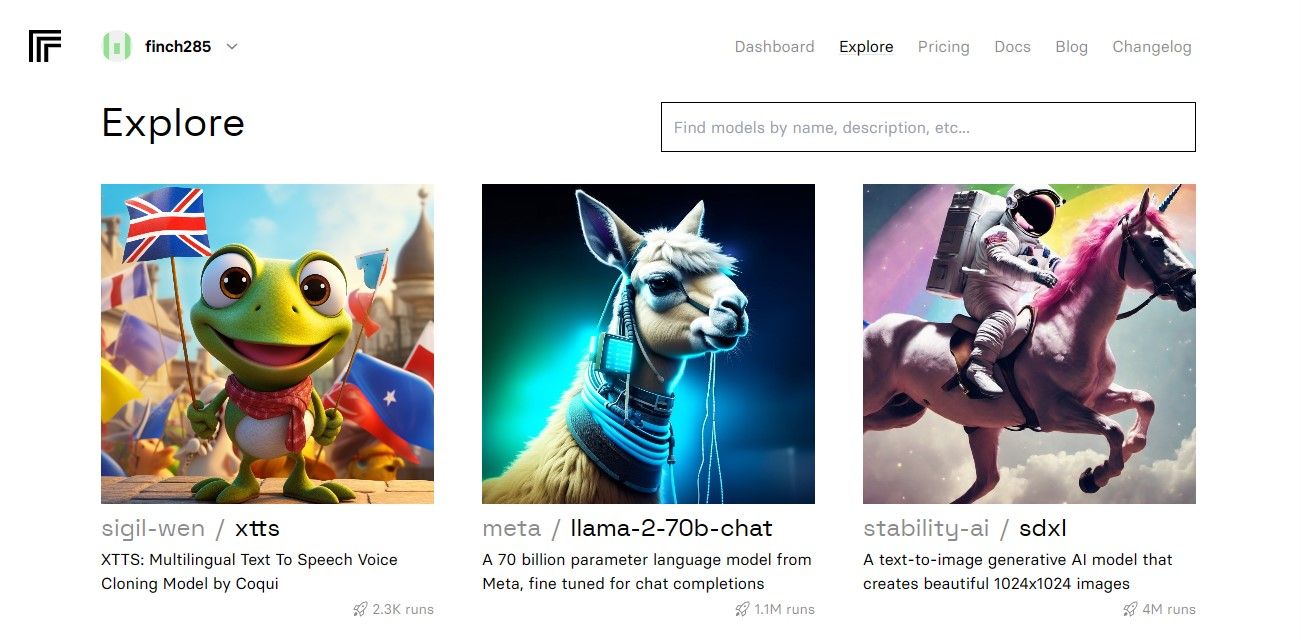
برای مشاهده نقاط پایانی Llama 2 API روی مدل lama-2–70b-chat کلیک کنید. روی دکمه API در نوار پیمایش مدل llama-2–70b-chat کلیک کنید. در سمت راست صفحه، روی دکمه پایتون کلیک کنید. با این کار به توکن API برای برنامه های پایتون دسترسی خواهید داشت.
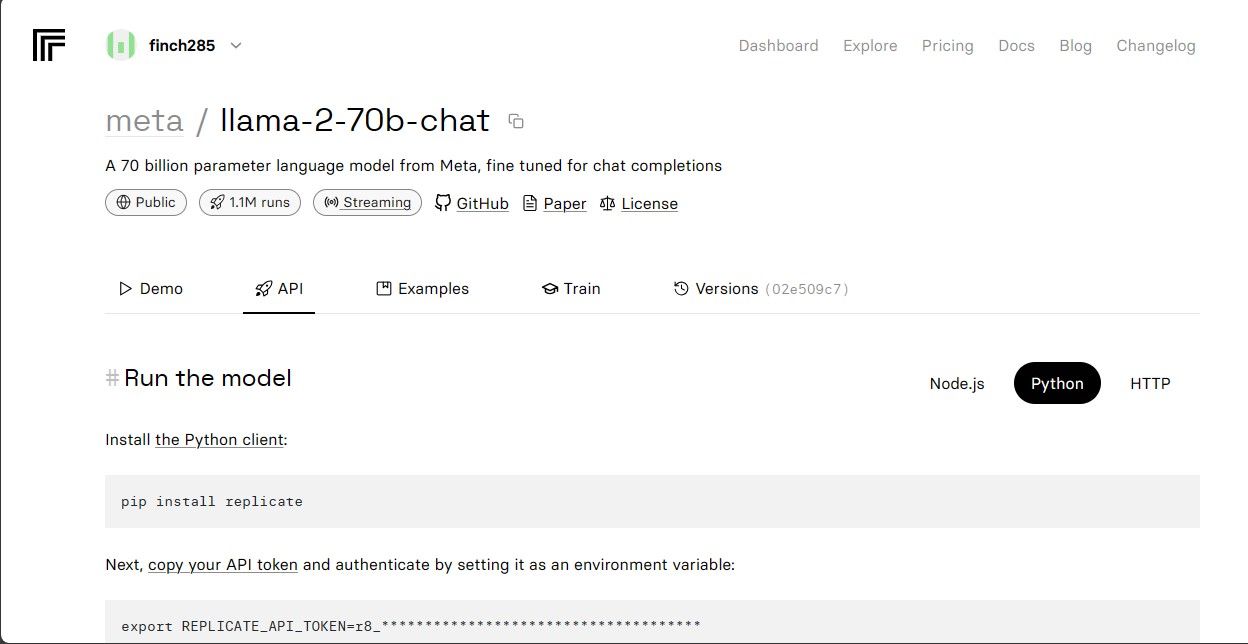
REPLICATE_API_TOKEN را کپی کنید و آن را برای استفاده در آینده ایمن ذخیره کنید.
کد منبع کامل در این مخزن GitHub موجود است.
ساخت چت بات
ابتدا یک فایل پایتون به نام llama_chatbot.py و یک فایل env (.env) ایجاد کنید. شما کد خود را در llama_chatbot.py می نویسید و کلیدهای مخفی و توکن های API خود را در فایل .env ذخیره می کنید.
در فایل llama_chatbot.py، کتابخانه ها را به صورت زیر وارد کنید.
import streamlit as st
import os
import replicate
سپس، متغیرهای سراسری مدل llama-2-70b-chat را تنظیم کنید.
# Global variables
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default='')
# Define model endpoints as independent variables
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default='')
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default='')
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default='')
در فایل .env، توکن Replicate و نقاط پایانی مدل را در قالب زیر اضافه کنید:
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
رمز Replicate خود را چسبانده و فایل .env را ذخیره کنید.
طراحی جریان گفتگوی چت بات
بسته به اینکه می خواهید مدل Llama 2 چه کاری انجام دهد، یک پیش درخواست برای شروع مدل Llama 2 ایجاد کنید. در این مورد، شما می خواهید مدل به عنوان یک دستیار عمل کند.
# Set Pre-propmt
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
تنظیمات صفحه را برای چت بات خود به صورت زیر تنظیم کنید:
# Set initial page configuration
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
تابعی بنویسید که متغیرهای وضعیت جلسه را مقداردهی اولیه و تنظیم کند.
# Constants
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
# Session State Variables
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPT
def setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
این تابع متغیرهای ضروری مانند chat_dialogue، pre_prompt، llm، top_p، max_seq_len و دما را در حالت جلسه تنظیم می کند. همچنین انتخاب مدل Llama 2 را بر اساس انتخاب کاربر انجام می دهد.
تابعی بنویسید تا محتوای نوار کناری برنامه Streamlit را ارائه کند.
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
این تابع هدر و متغیرهای تنظیم چت ربات Llama 2 را برای تنظیمات نمایش می دهد.
تابعی را که تاریخچه چت را رندر می کند در قسمت محتوای اصلی برنامه Streamlit بنویسید.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
این تابع از طریق chat_dialogue ذخیره شده در حالت جلسه تکرار می شود و هر پیام را با نقش مربوطه (کاربر یا دستیار) نمایش می دهد.
با استفاده از تابع زیر، ورودی کاربر را مدیریت کنید.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
این تابع یک فیلد ورودی را در اختیار کاربر قرار می دهد که می تواند پیام ها و سوالات خود را وارد کند. هنگامی که کاربر پیام را ارسال کرد، پیام در حالت جلسه با نقش کاربر به chat_dialogue اضافه می شود.
تابعی بنویسید که پاسخ هایی را از مدل Llama 2 تولید کرده و در ناحیه چت نمایش دهد.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
این تابع یک رشته تاریخچه مکالمه ایجاد می کند که شامل پیام های کاربر و دستیار قبل از فراخوانی تابع debounce_replicate_run برای دریافت پاسخ دستیار است. به طور مداوم پاسخ را در UI تغییر می دهد تا یک تجربه چت در زمان واقعی ارائه دهد.
تابع اصلی که مسئول رندر کردن کل برنامه Streamlit است را بنویسید.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
همه توابع تعریف شده را فراخوانی می کند تا وضعیت جلسه را تنظیم کند، نوار کناری، تاریخچه چت را ارائه دهد، ورودی کاربر را مدیریت کند و پاسخ های دستیار را به ترتیب منطقی تولید کند.
تابعی بنویسید تا تابع render_app را فراخوانی کند و پس از اجرای اسکریپت برنامه را شروع کند.
def main():
render_app()
if __name__ == "__main__":
main()
اکنون برنامه شما باید برای اجرا آماده باشد.
رسیدگی به درخواست های API
یک فایل utils.py در فهرست پروژه خود ایجاد کنید و تابع زیر را اضافه کنید:
import replicate
import time
# Initialize debounce variables
last_call_time = 0
debounce_interval = 2 # Set the debounce interval (in seconds)
def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)
current_time = time.time()
elapsed_time = current_time - last_call_time
if elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."
last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
این تابع یک مکانیسم debounce را انجام می دهد تا از درخواست های مکرر و بیش از حد API از ورودی کاربر جلوگیری کند.
سپس تابع پاسخ debounce را به صورت زیر در فایل llama_chatbot.py خود وارد کنید:
from utils import debounce_replicate_run
حالا اپلیکیشن را اجرا کنید:
streamlit run llama_chatbot.py
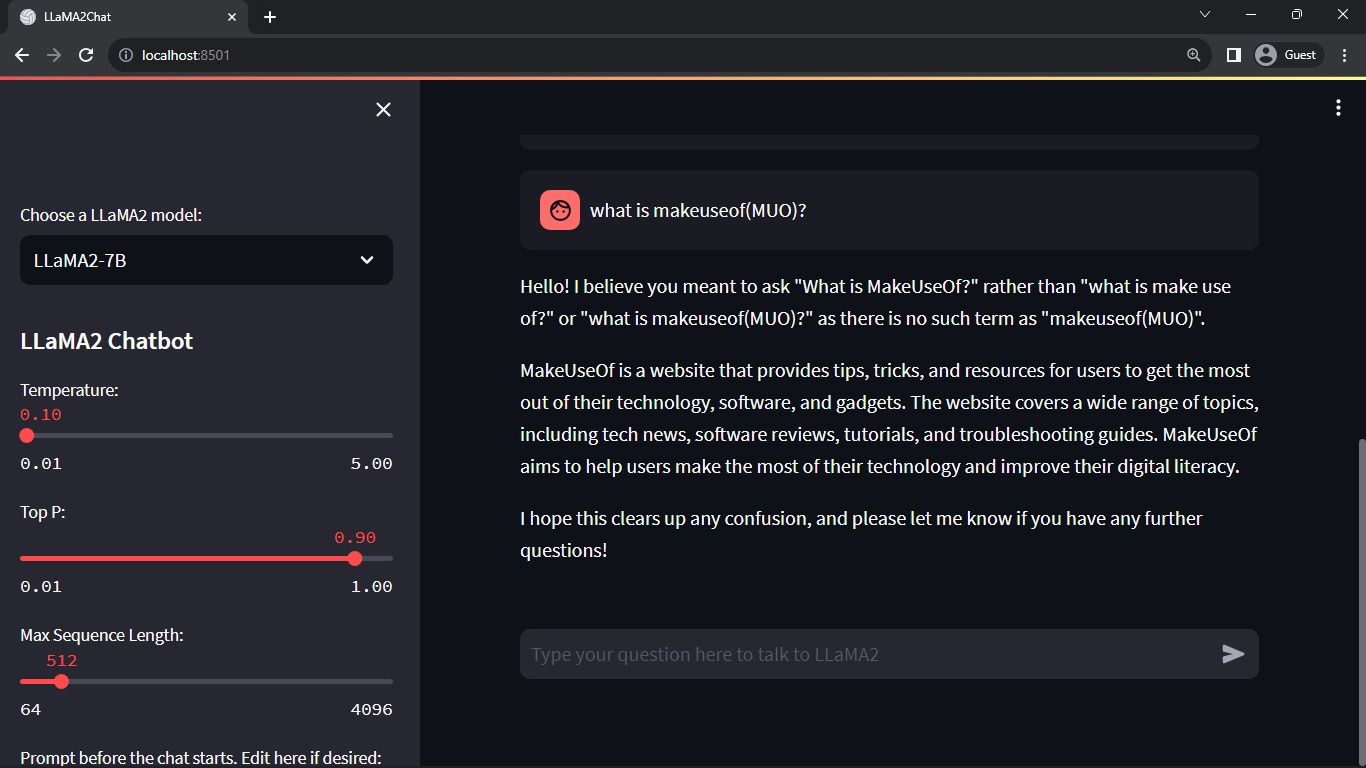
خروجی مورد انتظار:
خروجی یک مکالمه بین مدل و یک انسان را نشان می دهد.
کاربردهای دنیای واقعی چت ربات های Streamlit و Llama 2
برخی از نمونه های واقعی برنامه های Llama 2 عبارتند از:
- رباتهای چت: استفاده از آن برای ایجاد چترباتهای پاسخدهی انسانی که میتوانند مکالمههای بیدرنگ در مورد چندین موضوع انجام دهند، اعمال میشود.
- دستیارهای مجازی: استفاده از آن برای ایجاد دستیارهای مجازی که پرس و جوهای زبان انسانی را می فهمند و به آنها پاسخ می دهند، اعمال می شود.
- ترجمه زبان: استفاده از آن برای کارهای ترجمه زبان اعمال می شود.
- خلاصه سازی متن: استفاده از آن در خلاصه کردن متون بزرگ به متون کوتاه برای درک آسان کاربرد دارد.
- تحقیق: میتوانید با پاسخ دادن به سؤالات در طیف وسیعی از موضوعات، Llama 2 را برای اهداف تحقیقاتی به کار ببرید.
آینده هوش مصنوعی
با مدلهای بسته مانند GPT-3.5 و GPT-4، ساخت هر ماده با استفاده از LLM برای بازیکنان کوچک بسیار دشوار است زیرا دسترسی به API مدل GPT میتواند بسیار گران باشد.
گشودن مدلهای پیشرفته زبان بزرگ مانند Llama 2 به روی جامعه توسعهدهندگان تنها آغاز عصر جدیدی از هوش مصنوعی است. این امر منجر به اجرای خلاقانهتر و نوآورانهتر مدلها در برنامههای کاربردی در دنیای واقعی میشود که منجر به مسابقهای سریع برای دستیابی به ابر هوش مصنوعی (ASI) میشود.