با اجرای روشهای افزایش دادههای TensorFlow، از برازش بیش از حد جلوگیری کنید و دقت مدل یادگیری ماشین خود را افزایش دهید.
افزایش داده ها فرآیند اعمال تبدیل های مختلف به داده های آموزشی است. این به افزایش تنوع مجموعه داده و جلوگیری از برازش بیش از حد کمک می کند. تطبیق بیش از حد بیشتر زمانی اتفاق می افتد که داده های محدودی برای آموزش مدل خود دارید.
در اینجا، نحوه استفاده از ماژول افزایش داده های TensorFlow را برای تنوع بخشیدن به مجموعه داده ها یاد خواهید گرفت. این با ایجاد نقاط داده جدید که کمی متفاوت از داده های اصلی هستند، از برازش بیش از حد جلوگیری می کند.
مجموعه داده نمونه ای که استفاده خواهید کرد
شما از مجموعه داده های گربه ها و سگ ها از Kaggle استفاده خواهید کرد. این مجموعه داده شامل تقریباً 3000 تصویر از گربه و سگ است. این تصاویر به مجموعه های آموزشی، آزمایشی و اعتبار سنجی تقسیم می شوند.

برچسب 1.0 نشان دهنده یک سگ است در حالی که برچسب 0.0 نشان دهنده یک گربه است.
کد منبع کاملی که تکنیکهای افزایش داده را پیادهسازی میکند و کدی که وجود ندارد در مخزن GitHub موجود است.
نصب و وارد کردن TensorFlow
برای پیگیری، باید درک اولیه ای از پایتون داشته باشید. شما همچنین باید دانش اولیه یادگیری ماشین را داشته باشید. اگر به تجدید نظر نیاز دارید، ممکن است بخواهید برخی از آموزشهای یادگیری ماشین را دنبال کنید.
Google Colab را باز کنید. نوع زمان اجرا را به GPU تغییر دهید. سپس دستور جادویی زیر را در اولین سلول کد اجرا کنید تا TensorFlow را در محیط خود نصب کنید.
!pip install tensorflow
TensorFlow و ماژول ها و کلاس های مربوط به آن را وارد کنید.
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
tensorflow.keras.preprocessing.image شما را قادر می سازد تا داده ها را در مجموعه داده خود افزایش دهید.
ایجاد نمونه هایی از کلاس ImageDataGenerator
یک نمونه از کلاس ImageDataGenerator برای داده های قطار ایجاد کنید. شما از این شی برای پیش پردازش داده های آموزشی استفاده خواهید کرد. در طول آموزش مدل، دسته ای از داده های تصویر افزوده را در زمان واقعی تولید می کند.
در کار طبقه بندی گربه یا سگ بودن یک تصویر، می توانید از تکنیک های ورق زدن، عرض تصادفی، ارتفاع تصادفی، روشنایی تصادفی و بزرگنمایی داده ها استفاده کنید. این تکنیک ها داده های جدیدی تولید می کنند که حاوی تغییراتی از داده های اصلی است که سناریوهای دنیای واقعی را نشان می دهد.
# define the image data generator for training
train_datagen = ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
width_shift_range=0.2,
height_shift_range=0.2,
brightness_range=[0.2,1.0],
zoom_range=0.2)
نمونه دیگری از کلاس ImageDataGenerator برای داده های تست ایجاد کنید. شما به پارامتر rescale نیاز دارید. مقادیر پیکسل تصاویر آزمایشی را برای مطابقت با فرمت استفاده شده در طول آموزش عادی می کند.
# define the image data generator for testing
test_datagen = ImageDataGenerator(rescale=1./255)
یک نمونه نهایی از کلاس ImageDataGenerator برای داده های اعتبار سنجی ایجاد کنید. مقیاس داده های اعتبارسنجی به همان روشی که داده های آزمایشی هستند.
# define the image data generator for validation
validation_datagen = ImageDataGenerator(rescale=1./255)
شما نیازی به اعمال سایر تکنیکهای تقویت برای دادههای آزمایش و اعتبارسنجی ندارید. این به این دلیل است که مدل از داده های آزمون و اعتبارسنجی فقط برای اهداف ارزیابی استفاده می کند. آنها باید توزیع اصلی داده را منعکس کنند.
در حال بارگیری داده های شما
یک شی DirectoryIterator از فهرست آموزشی ایجاد کنید. دسته هایی از تصاویر تقویت شده را تولید می کند. سپس دایرکتوری که داده های آموزشی را ذخیره می کند را مشخص کنید. اندازه تصاویر را به اندازه ثابت 64×64 پیکسل تغییر دهید. تعداد تصاویری را که هر دسته استفاده می کند را مشخص کنید. در آخر، نوع برچسب را مشخص کنید که باینری باشد (یعنی گربه یا سگ).
# defining the training directory
train_data = train_datagen.flow_from_directory(directory=r'/content/drive/MyDrive/cats_and_dogs_filtered/train',
target_size=(64, 64),
batch_size=32,
class_mode='binary')
یک شی DirectoryIterator دیگر از دایرکتوری تست ایجاد کنید. پارامترها را با مقادیر مشابه داده های آموزشی تنظیم کنید.
# defining the testing directory
test_data = test_datagen.flow_from_directory(directory='/content/drive/MyDrive/cats_and_dogs_filtered/test',
target_size=(64, 64),
batch_size=32,
class_mode='binary')
یک شیء DirectoryIterator نهایی از دایرکتوری اعتبارسنجی ایجاد کنید. پارامترها مانند پارامترهای داده های آموزش و آزمایش باقی می مانند.
# defining the validation directory
validation_data = validation_datagen.flow_from_directory(directory='/content/drive/MyDrive/cats_and_dogs_filtered/validation',
target_size=(64, 64),
batch_size=32,
class_mode='binary')
تکرار کننده های دایرکتوری اعتبارسنجی و مجموعه داده های آزمایشی را افزایش نمی دهند.
تعریف مدل خود
معماری شبکه عصبی خود را تعریف کنید. از شبکه عصبی کانولوشن (CNN) استفاده کنید. CNN ها برای تشخیص الگوها و ویژگی ها در تصاویر طراحی شده اند.
model = Sequential()
# convolutional layer with 32 filters of size 3x3
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
# max pooling layer with pool size 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# convolutional layer with 64 filters of size 3x3
model.add(Conv2D(64, (3, 3), activation='relu'))
# max pooling layer with pool size 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# flatten the output from the convolutional and pooling layers
model.add(Flatten())
# fully connected layer with 128 units and ReLU activation
model.add(Dense(128, activation='relu'))
# randomly drop out 50% of the units to prevent overfitting
model.add(Dropout(0.5))
# output layer with sigmoid activation (binary classification)
model.add(Dense(1, activation='sigmoid'))
مدل را با استفاده از تابع تلفات متقابل آنتروپی باینری کامپایل کنید. مشکلات طبقه بندی باینری معمولاً از آن استفاده می کنند. برای بهینه ساز، از بهینه ساز Adam استفاده کنید. این یک الگوریتم بهینه سازی نرخ یادگیری تطبیقی است. در نهایت مدل را از نظر دقت ارزیابی کنید.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
خلاصه ای از معماری مدل را در کنسول چاپ کنید.
model.summary()
تصویر زیر تجسم معماری مدل را نشان می دهد.
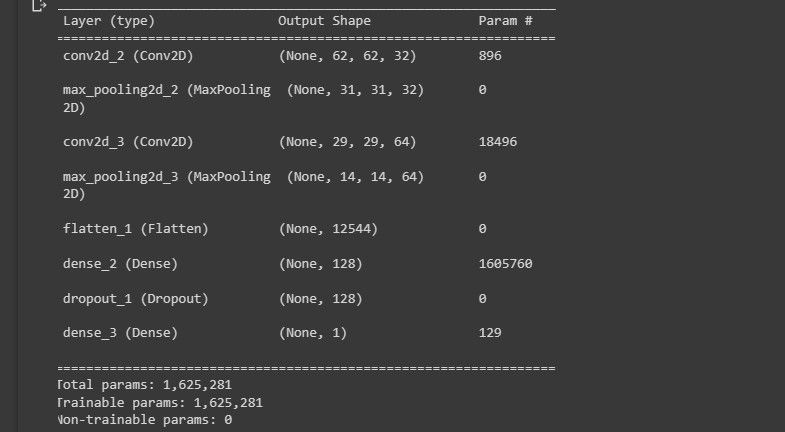
این به شما یک دید کلی از طراحی مدل شما می دهد.
آموزش مدل خود
با استفاده از روش fit() مدل را آموزش دهید. تعداد مراحل در هر دوره را به تعداد نمونه های آموزشی تقسیم بر batch_size تنظیم کنید. همچنین داده های اعتبارسنجی و تعداد مراحل اعتبار سنجی را تنظیم کنید.
# Train the model on the training data
history = model.fit(train_data,
steps_per_epoch=train_data.n // train_data.batch_size,
epochs=50,
validation_data=validation_data,
validation_steps=validation_data.n // validation_data.batch_size)
کلاس ImageDataGenerator افزایش داده را به داده های آموزشی در زمان واقعی اعمال می کند. این باعث می شود روند آموزش مدل کندتر شود.
ارزیابی مدل شما
عملکرد مدل خود را بر روی داده های آزمون با استفاده از روش ()value ارزیابی کنید. همچنین فقدان تست و دقت را روی کنسول چاپ کنید.
test_loss, test_acc = model.evaluate(test_data,
steps=test_data.n // test_data.batch_size)
print(f'Test loss: {test_loss}')
print(f'Test accuracy: {test_acc}')
تصویر زیر عملکرد مدل را نشان می دهد.

این مدل روی دادههایی که هرگز دیده نشدهاند به خوبی عمل میکند.
وقتی کدی را اجرا میکنید که تکنیکهای تقویت دادهها را پیادهسازی نمیکند، دقت آموزش مدل 1 است. به این معنی که بیش از حد برازش میکند. همچنین بر روی داده هایی که قبلاً ندیده بود عملکرد ضعیفی دارد. این به این دلیل است که ویژگی های مجموعه داده را می آموزد.
چه زمانی افزایش داده ها مفید نیست؟
- هنگامی که مجموعه داده از قبل متنوع و بزرگ است: افزایش داده ها اندازه و تنوع یک مجموعه داده را افزایش می دهد. اگر مجموعه داده از قبل بزرگ و متنوع باشد، افزایش داده مفید نخواهد بود.
- وقتی مجموعه داده خیلی کوچک است: افزایش داده نمی تواند ویژگی های جدیدی ایجاد کند که در مجموعه داده اصلی وجود ندارد. بنابراین، نمی تواند مجموعه داده های کوچکی را که فاقد اکثر ویژگی هایی است که مدل برای یادگیری نیاز دارد، جبران کند.
- هنگامی که نوع افزایش داده نامناسب است: برای مثال، چرخش تصاویر ممکن است در جایی که جهت اشیاء مهم است مفید نباشد.
TensorFlow چه توانایی هایی دارد
TensorFlow یک کتابخانه متنوع و قدرتمند است. این می تواند مدل های یادگیری عمیق پیچیده را آموزش دهد و می تواند بر روی طیف وسیعی از دستگاه ها از تلفن های هوشمند گرفته تا خوشه های سرور اجرا شود. این به دستگاه های محاسباتی قدرتمندی که از یادگیری ماشینی استفاده می کنند کمک کرده است.