
وقتی یک API آن را قطع نمیکند، همیشه میتوانید به خراش دادن HTML متوسل شوید و Rust میتواند به شما کمک کند.
Web scraping یک تکنیک محبوب برای جمع آوری مقادیر زیادی از داده ها از صفحات وب به سرعت و کارآمد است. در غیاب API، اسکراپینگ وب می تواند بهترین رویکرد بعدی باشد.
سرعت Rust و ایمنی حافظه این زبان را برای ساخت اسکریپرهای وب ایده آل می کند. Rust خانه بسیاری از کتابخانه های قدرتمند تجزیه و استخراج داده است و قابلیت های مدیریت خطای قوی آن برای جمع آوری داده های وب کارآمد و قابل اعتماد مفید است.
خراش دادن وب در Rust
بسیاری از کتابخانه های محبوب از web scraping در Rust پشتیبانی می کنند، از جمله reqwest، scraper، select و html5ever. اکثر توسعه دهندگان Rust عملکردهای reqwest و scraper را برای خراش دادن وب خود ترکیب می کنند.
کتابخانه reqwest عملکردی را برای درخواست HTTP به سرورهای وب فراهم می کند. Reqwest بر روی جعبه هایپر داخلی Rust ساخته شده است در حالی که یک API سطح بالا برای ویژگی های استاندارد HTTP ارائه می دهد.
Scraper یک کتابخانه خراش دهنده وب قدرتمند است که اسناد HTML و XML را تجزیه می کند و داده ها را با استفاده از انتخابگرهای CSS و عبارات XPath استخراج می کند.
پس از ایجاد یک پروژه Rust جدید با دستور cargo new، جعبههای reqwest و scraper را به بخش وابستگیهای فایل cargo.toml خود اضافه کنید:
[dependencies]
reqwest = {version = "0.11", features = ["blocking"]}
scraper = "0.12.0"
از reqwest برای ارسال درخواست های HTTP و scraper برای تجزیه استفاده خواهید کرد.
بازیابی صفحات وب با Reqwest
قبل از تجزیه آن برای بازیابی داده های خاص، درخواستی برای محتویات یک صفحه وب ارسال می کنید.
می توانید یک درخواست GET ارسال کنید و منبع HTML یک صفحه را با استفاده از تابع متن در تابع get کتابخانه reqwest بازیابی کنید:
fn retrieve_html() -> String {
let response = get("https://news.ycombinator.com").unwrap().text().unwrap();
return response;
}
تابع get درخواست را به صفحه وب می فرستد و تابع text متن HTML را برمی گرداند.
تجزیه HTML با Scraper
تابع retrieve_html متن HTML را برمیگرداند و برای بازیابی دادههای خاصی که نیاز دارید، باید متن HTML را تجزیه کنید.
Scraper عملکردی برای تعامل با HTML در ماژول های Html و Selector فراهم می کند. ماژول Html عملکردی را برای تجزیه سند و ماژول Selector عملکردی را برای انتخاب عناصر خاص از HTML فراهم می کند.
در اینجا نحوه بازیابی تمام عناوین یک صفحه آمده است:
use scraper::{Html, Selector};
fn main() {
let response = reqwest::blocking::get(
"https://news.ycombinator.com/").unwrap().text().unwrap();
// parse the HTML document
let doc_body = Html::parse_document(&response);
// select the elements with titleline class
let title = Selector::parse(".titleline").unwrap();
for title in doc_body.select(&title) {
let titles = title.text().collect::<Vec<_>>();
println!("{}", titles[0])
}
}
تابع parse_document ماژول Html متن HTML را تجزیه می کند و تابع Parse ماژول Selector عناصر را با انتخابگر CSS مشخص شده (در این مورد، کلاس عنوان) انتخاب می کند.
حلقه for از میان این عناصر عبور می کند و اولین بلوک متن را از هر کدام چاپ می کند.
در اینجا نتیجه عمل آمده است:
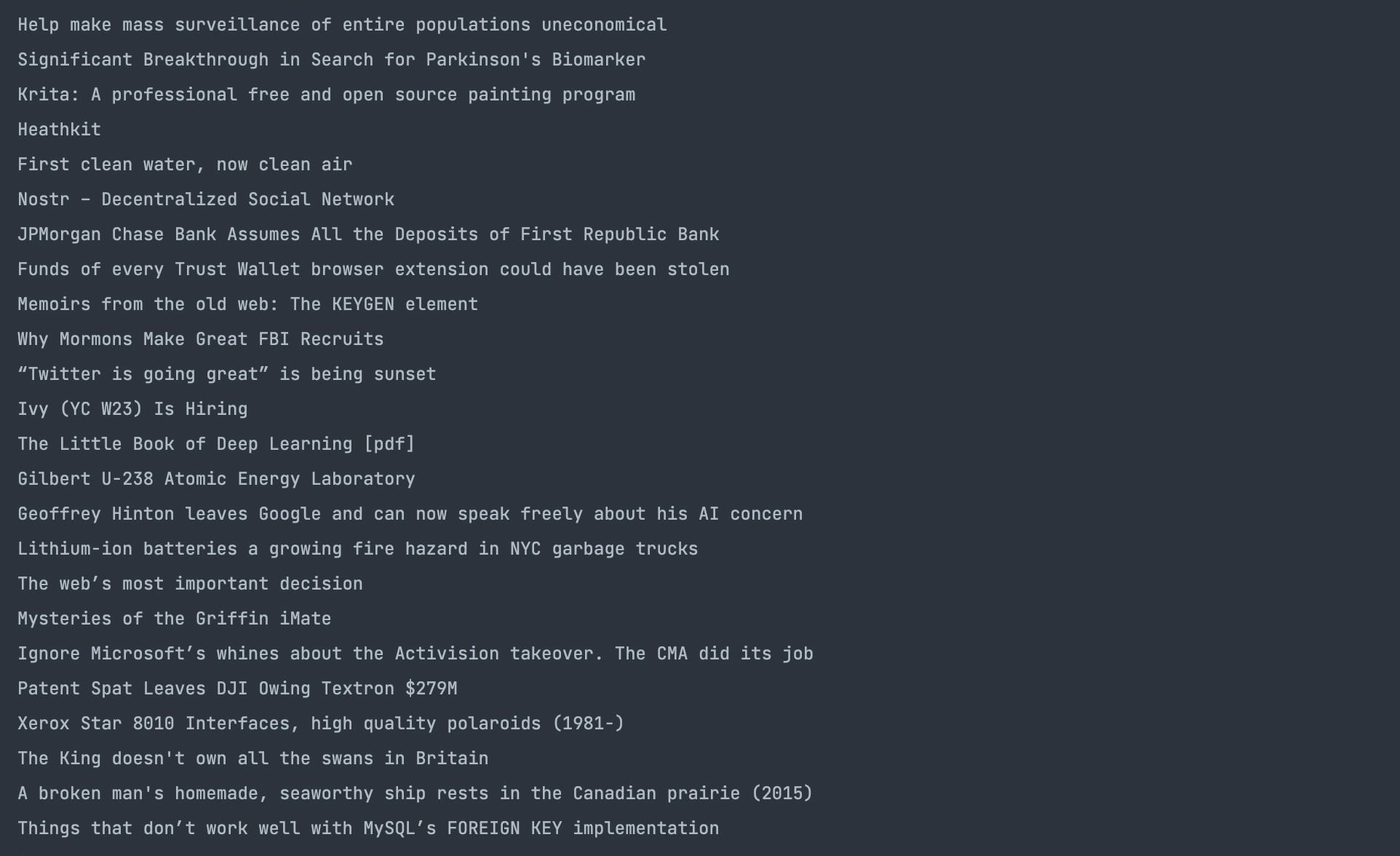
انتخاب ویژگی ها با Scraper
برای انتخاب یک مقدار مشخصه، عناصر مورد نیاز را مانند قبل بازیابی کنید و از روش attr در نمونه مقدار برچسب استفاده کنید:
use reqwest::blocking::get;
use scraper::{Html, Selector};
fn main() {
let response = get("https://news.ycombinator.com").unwrap().text().unwrap();
let html_doc = Html::parse_document(&response);
let class_selector = Selector::parse(".titleline").unwrap();
for element in html_doc.select(&class_selector) {
let link_selector = Selector::parse("a").unwrap();
for link in element.select(&link_selector) {
if let Some(href) = link.value().attr("href") {
println!("{}", href);
}
}
}
}
پس از انتخاب عناصر با کلاس عنوان با استفاده از تابع تجزیه، حلقه for آنها را طی می کند. در داخل حلقه، کد یک تگ واکشی می کند و ویژگی href را با تابع attr انتخاب می کند.
تابع اصلی این پیوندها را با نتیجه ای مانند این چاپ می کند:

شما می توانید برنامه های وب پیچیده در Rust بسازید
اخیراً، Rust به عنوان زبانی برای توسعه وب از توسعه برنامه های front-end تا سمت سرور استفاده شده است.
میتوانید از اسمبلی وب برای ساخت برنامههای وب تمام پشته با کتابخانههایی مانند Yew و Percy یا ساخت برنامههای سمت سرور با Actix، Rocket و میزبان کتابخانهها در اکوسیستم Rust استفاده کنید که قابلیتهایی را برای ساخت برنامههای وب ارائه میکنند.