
یادگیری ماشینی می تواند یک مفهوم انتزاعی باشد، بنابراین با کاوش در این الگوریتم های مختلف با آن کنار بیایید.
آیا تا به حال فکر کرده اید که ماشین های خودران، چت ربات ها و توصیه های خودکار نتفلیکس چگونه کار می کنند؟ این پیشرفتهای فنآوری مفید، محصولات یادگیری ماشینی هستند.
این نوع هوش مصنوعی کامپیوترها را برای مطالعه رفتار انسان و استفاده از الگوریتم ها برای تصمیم گیری هوشمندانه بدون مداخله آموزش می دهد. الگوریتمها مستقل از دادههای ورودی یاد میگیرند و خروجی منطقی را بر اساس پویایی یک مجموعه داده آموزشی پیشبینی میکنند.
در اینجا تعدادی از بهترین الگوریتم های یادگیری ماشینی وجود دارد که به ایجاد و آموزش سیستم های کامپیوتری هوشمند کمک می کند.
اهمیت الگوریتم ها در یادگیری ماشینی
الگوریتم یادگیری ماشینی مجموعه ای از دستورالعمل هایی است که برای کمک به کامپیوتر در تقلید رفتار انسان استفاده می شود. چنین الگوریتم هایی می توانند کارهای پیچیده ای را با کمک انسان کم یا صفر انجام دهند.
به جای نوشتن کد برای هر کار، الگوریتم از داده هایی که به مدل معرفی می کنید، منطق می سازد. با توجه به یک مجموعه داده به اندازه کافی بزرگ، یک الگو را شناسایی می کند و به آن اجازه می دهد تصمیمات منطقی بگیرد و خروجی ارزشمند را پیش بینی کند.
سیستم های مدرن از چندین الگوریتم یادگیری ماشینی استفاده می کنند که هر کدام مزایای عملکردی خاص خود را دارند. الگوریتم ها همچنین در دقت، داده های ورودی و موارد استفاده متفاوت هستند. به این ترتیب، دانستن اینکه از کدام الگوریتم استفاده شود، مهم ترین گام برای ساختن یک مدل یادگیری ماشینی موفق است.
1. رگرسیون لجستیک
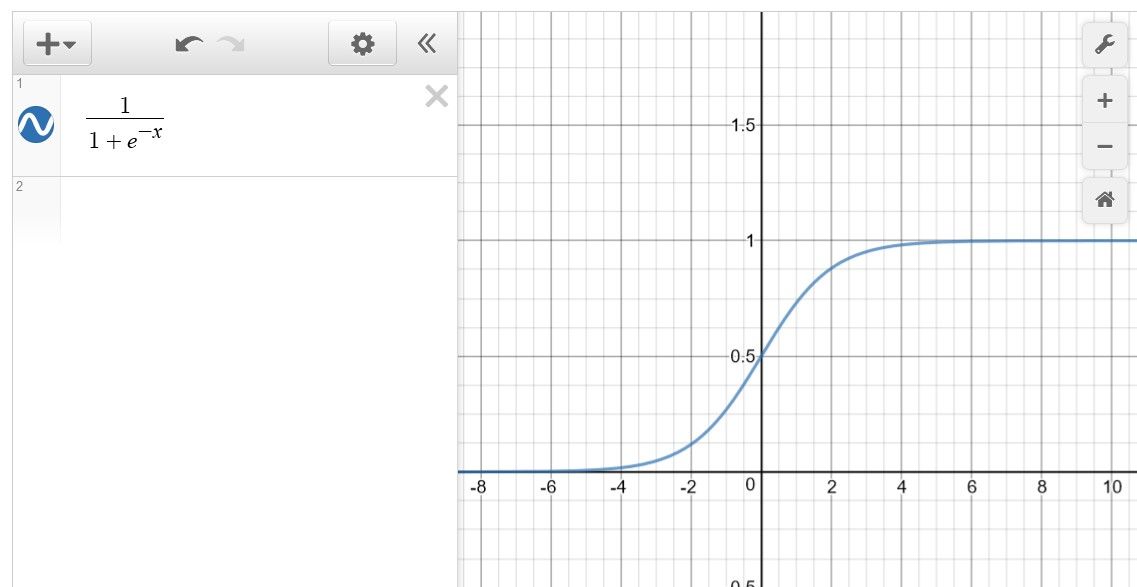
این الگوریتم که به عنوان رگرسیون لجستیک دو جمله ای نیز شناخته می شود، احتمال موفقیت یا شکست یک رویداد را پیدا می کند. زمانی که متغیر وابسته باینری باشد، عموماً روش go-to است. علاوه بر این، نتایج معمولاً به صورت درست/نادرست یا بله/خیر پردازش میشوند.
برای استفاده از این مدل آماری، باید مجموعه داده های برچسب گذاری شده را به دسته های مجزا مطالعه و دسته بندی کنید. یک ویژگی چشمگیر این است که شما می توانید رگرسیون لجستیک را به چندین کلاس گسترش دهید و یک دید واقعی از پیش بینی کلاس ها بر اساس احتمالات ارائه دهید.
رگرسیون لجستیک برای طبقه بندی رکوردهای ناشناخته و مجموعه داده های ساده بسیار سریع و دقیق است. همچنین در تفسیر ضرایب مدل استثنایی است. علاوه بر این، رگرسیون لجستیک در سناریوهایی که مجموعه داده ها به صورت خطی قابل تفکیک هستند، بهترین کار را دارد.
با استفاده از این الگوریتم، می توانید به راحتی مدل ها را برای انعکاس داده های جدید به روز کنید و از استنتاج برای تعیین رابطه بین ویژگی ها استفاده کنید. همچنین کمتر مستعد بیش از حد برازش است، در صورت وجود یک تکنیک منظم سازی دارد و به قدرت محاسباتی کمی نیاز دارد.
یکی از محدودیت های بزرگ رگرسیون لجستیک این است که یک رابطه خطی بین متغیرهای وابسته و مستقل را فرض می کند. این آن را برای مسائل غیر خطی نامناسب می کند زیرا فقط توابع گسسته را با استفاده از سطح تصمیم خطی پیش بینی می کند. در نتیجه، الگوریتمهای قدرتمندتر ممکن است با وظایف پیچیدهتر شما سازگاری بیشتری داشته باشند.
2. درخت تصمیم
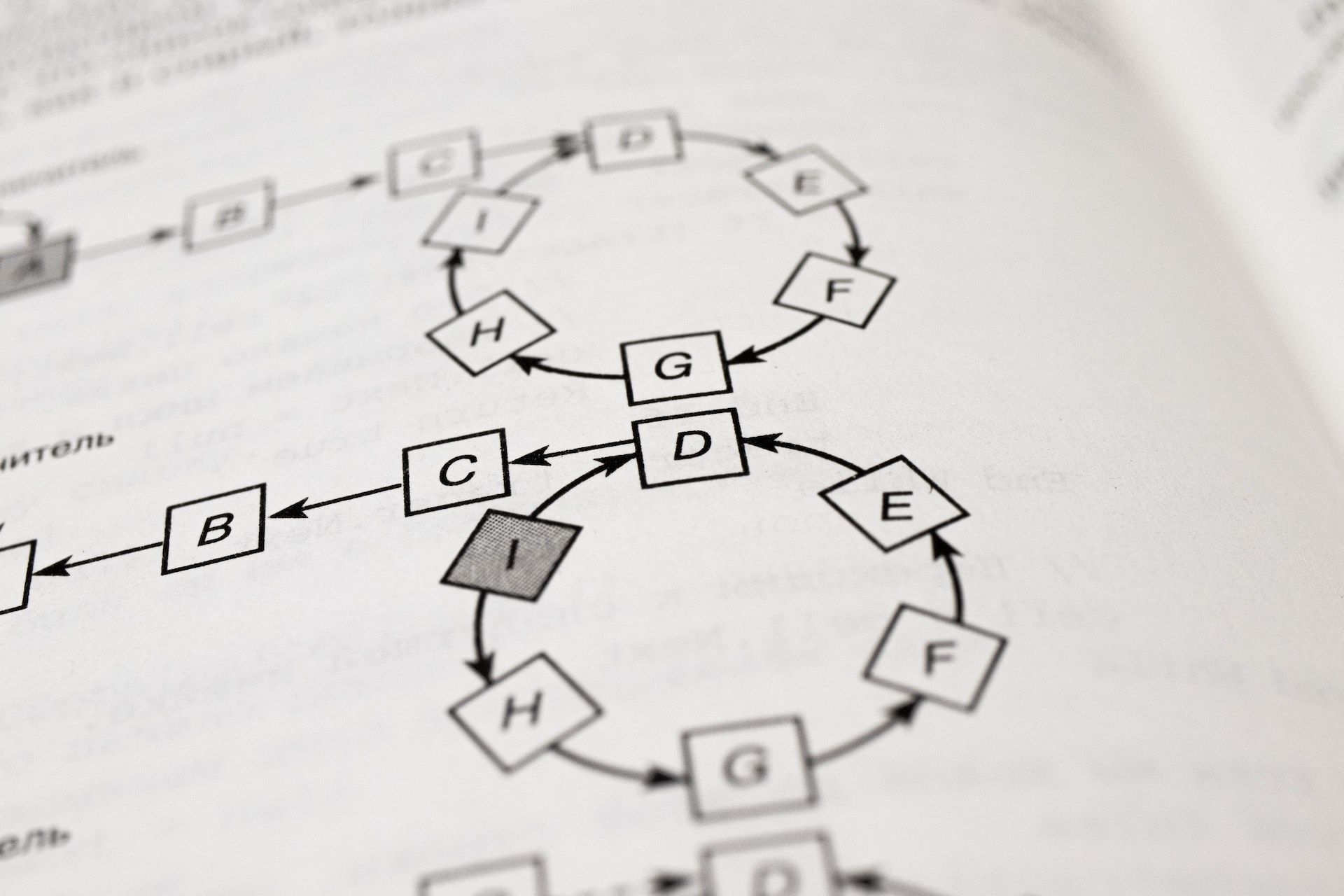
این نام از رویکرد درختی آن گرفته شده است. شما می توانید از چارچوب درخت تصمیم برای طبقه بندی و مشکلات رگرسیون استفاده کنید. با این حال، برای حل مسائل طبقه بندی کاربردی تر است.
مانند یک درخت، با گره ریشه شروع می شود که مجموعه داده را نشان می دهد. شاخه ها بیانگر قوانینی هستند که فرآیند یادگیری را هدایت می کنند. این شاخه ها که گره های تصمیم نامیده می شوند، سوالات بله یا خیر هستند که به شاخه های دیگر منتهی می شوند یا به گره های برگ ختم می شوند.
هر گره برگ نشان دهنده نتیجه ممکن از مجموعه ای از تصمیمات است. گره های برگ و گره های تصمیم دو نهاد اصلی هستند که در پیش بینی یک نتیجه از اطلاعات داده شده نقش دارند. از این رو، خروجی یا تصمیم نهایی بر اساس ویژگی های مجموعه داده است.
درختهای تصمیم، الگوریتمهای یادگیری ماشینی تحت نظارت هستند. این نوع الگوریتم ها از کاربر می خواهند که توضیح دهد ورودی چیست. آنها همچنین به شرح خروجی مورد انتظار از داده های آموزشی نیاز دارند.
به بیان ساده، این الگوریتم یک نمایش گرافیکی از گزینه های مختلف است که توسط شرایط از پیش تعیین شده برای دستیابی به تمام راه حل های ممکن برای یک مسئله هدایت می شود. به این ترتیب، سؤالات پرسیده شده برای رسیدن به یک راه حل ساخته شده است. درختان تصمیم فرآیند فکر انسان را تقلید می کنند تا با استفاده از قوانین ساده به یک حکم منطقی برسند.
نقطه ضعف اصلی این الگوریتم این است که مستعد بی ثباتی است. یک تغییر دقیقه در داده ها می تواند باعث اختلال بزرگ در ساختار شود. به این ترتیب، شما باید راه های مختلفی را برای به دست آوردن مجموعه داده های ثابت برای پروژه های خود بررسی کنید.
3. الگوریتم K-NN
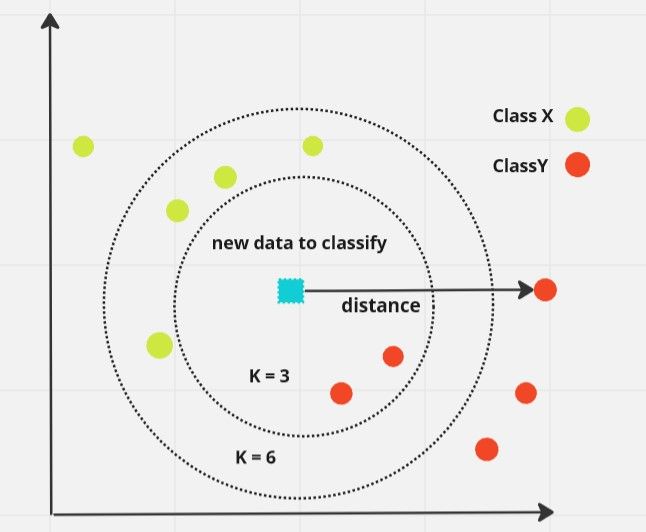
K-NN ثابت کرده است که یک الگوریتم چند وجهی برای مقابله با بسیاری از مشکلات دنیای واقعی مفید است. علیرغم اینکه یکی از ساده ترین الگوریتم های یادگیری ماشینی است، برای بسیاری از صنایع، از امنیت گرفته تا امور مالی و اقتصادی، مفید است.
همانطور که از نام آن پیداست، K-Nearest Neighbor با فرض شباهت بین داده های همسایه جدید و موجود، به عنوان یک طبقه بندی کننده عمل می کند. سپس مورد جدید را در همان دسته یا مشابه نزدیکترین داده های موجود قرار می دهد.
توجه به این نکته مهم است که K-NN یک الگوریتم ناپارامتریک است. در مورد داده های اساسی فرضیات نمی کند. الگوریتم یادگیرنده تنبل نیز نامیده می شود، بلافاصله از داده های آموزشی یاد نمی گیرد. در عوض، مجموعه داده های فعلی را ذخیره می کند و منتظر می ماند تا داده های جدید را دریافت کند. سپس بر اساس مجاورت و شباهت، طبقه بندی هایی را انجام می دهد.
K-NN عملی است و مردم از آن در زمینه های مختلف استفاده می کنند. در مراقبت های بهداشتی، این الگوریتم می تواند خطرات احتمالی سلامتی را بر اساس محتمل ترین بیان ژن یک فرد پیش بینی کند. در امور مالی، متخصصان از K-NN برای پیش بینی بازار سهام و حتی نرخ ارز استفاده می کنند.
عیب اصلی استفاده از این الگوریتم این است که نسبت به سایر الگوریتمهای یادگیری ماشینی، حافظه فشردهتری دارد. همچنین در مدیریت داده های پیچیده و با ابعاد بالا مشکل دارد.
با این وجود، K-NN انتخاب خوبی باقی می ماند زیرا به راحتی تطبیق می یابد، به راحتی الگوها را شناسایی می کند و به شما امکان می دهد تا داده های زمان اجرا را بدون تأثیر بر دقت پیش بینی تغییر دهید.
4. K-Means

K-Means یک الگوریتم یادگیری بدون نظارت است که مجموعه داده های بدون برچسب را در خوشه های منحصر به فرد گروه بندی می کند. ورودی را دریافت می کند، فاصله بین نقاط داده را به حداقل می رساند و داده ها را بر اساس اشتراکات جمع می کند.
برای وضوح، یک خوشه مجموعه ای از نقاط داده است که به دلیل شباهت های خاص در یک گروه قرار می گیرند. فاکتور “K” به سیستم می گوید که به چند خوشه نیاز دارد.
یک تصویر عملی از نحوه عملکرد این کار شامل تجزیه و تحلیل گروهی از بازیکنان فوتبال است. می توانید از این الگوریتم برای ایجاد و تقسیم فوتبالیست ها به دو خوشه استفاده کنید: فوتبالیست های خبره و فوتبالیست های آماتور.
الگوریتم K-Means چندین کاربرد در زندگی واقعی دارد. می توانید از آن برای دسته بندی نمرات دانش آموزان، انجام تشخیص های پزشکی و نمایش نتایج موتور جستجو استفاده کنید. به طور خلاصه، در تجزیه و تحلیل مقادیر زیادی از داده ها و تقسیم آنها به خوشه های منطقی برتری دارد.
یکی از پیامدهای استفاده از این الگوریتم این است که نتایج اغلب ناسازگار هستند. این وابسته به ترتیب است، بنابراین هرگونه تغییر در ترتیب مجموعه داده های موجود می تواند بر نتیجه آن تأثیر بگذارد. علاوه بر این، فاقد اثر یکنواخت است و فقط می تواند داده های عددی را مدیریت کند.
با وجود این محدودیت ها، K-Means یکی از بهترین الگوریتم های یادگیری ماشینی است. برای تقسیم بندی مجموعه داده ها عالی است و به دلیل سازگاری آن قابل اعتماد است.
انتخاب بهترین الگوریتم برای شما
به عنوان یک مبتدی، ممکن است برای حل کردن بهترین الگوریتم به کمک نیاز داشته باشید. این تصمیم در دنیایی پر از انتخاب های خارق العاده چالش برانگیز است. با این حال، برای شروع، باید انتخاب خود را بر اساس چیزی غیر از ویژگی های فانتزی الگوریتم قرار دهید.
در عوض، شما باید اندازه الگوریتم، ماهیت داده ها، فوریت کار و الزامات عملکرد را در نظر بگیرید. این عوامل، از جمله، به شما کمک می کنند تا الگوریتم کاملی را برای پروژه خود تعیین کنید.