برای تولید کننده تصویر هوش مصنوعی پولی پرداخت نکنید.
خلاصه عناوین
- کرایون
- Stable Diffusion 1.5
- دریم شیپر
- InvokeAI
- سفر باز
مدلهای تولید متن به تصویر مبتنی بر هوش مصنوعی در همه جا وجود دارند و دسترسی روزانه آسانتر میشود. در حالی که بازدید از یک وبسایت و ایجاد تصویر مورد نظر آسان است، اگر میخواهید کنترل بیشتری بر فرآیند تولید داشته باشید، مولدهای متن به تصویر منبع باز بهترین گزینه هستند.
ده ها مولد متن به تصویر هوش مصنوعی رایگان و منبع باز در اینترنت موجود است که در انواع خاصی از تصاویر تخصص دارند. بنابراین، ما این انبوه را بررسی کردهایم و بهترین تولیدکنندههای متن به تصویر AI منبع باز را پیدا کردهایم که میتوانید همین الان امتحان کنید.
1 کریون
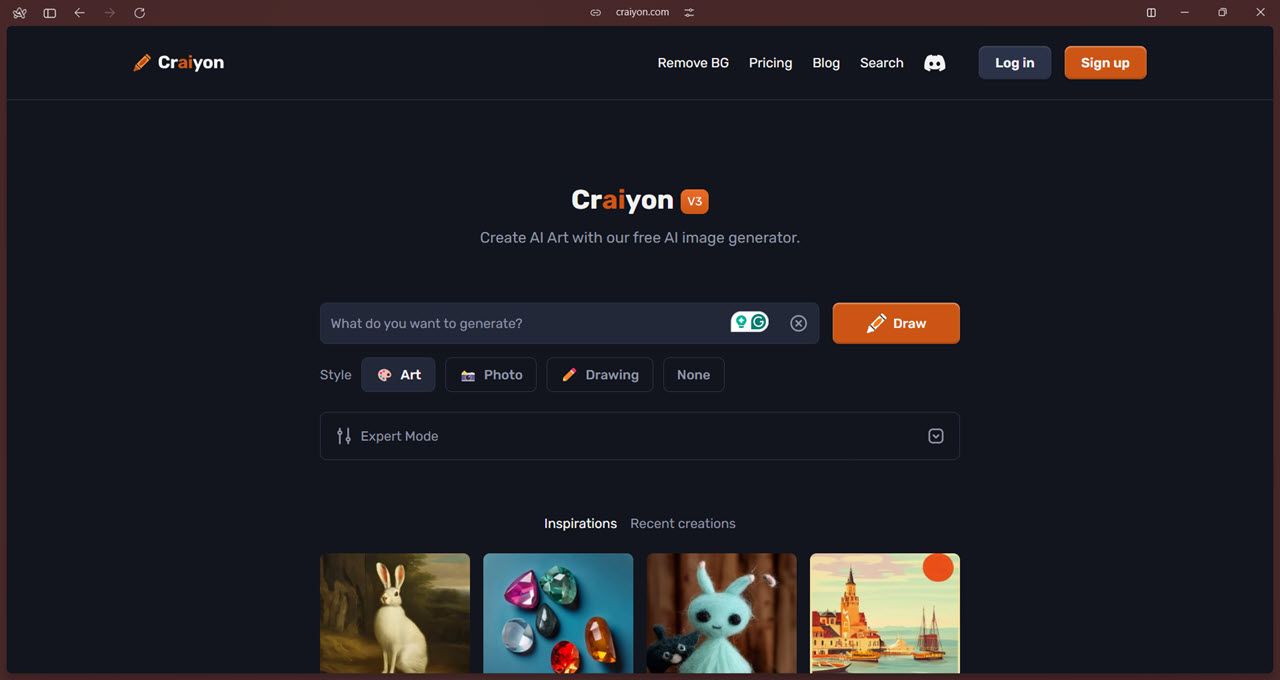
Craiyon یکی از در دسترس ترین تولیدکنندگان تصویر AI منبع باز است. این بر اساس DALL-E Mini است، و در حالی که می توانید مخزن Github را شبیه سازی کنید و مدل را به صورت محلی روی رایانه خود نصب کنید، به نظر می رسد Craiyon این رویکرد را به نفع وب سایت خود کنار گذاشته است.
مخزن رسمی Github از ژوئن 2022 به روز نشده است، اما آخرین مدل هنوز به صورت رایگان در سایت رسمی Craiyon در دسترس است. هیچ برنامه اندروید یا iOS نیز وجود ندارد.
از نظر عملکرد، تمام گزینه های معمولی را که از یک تولید کننده تصویر هوش مصنوعی انتظار دارید، مشاهده خواهید کرد. هنگامی که درخواست خود را وارد کردید و تصویری دریافت کردید، میتوانید از ویژگی ارتقاء برای دریافت یک کپی با وضوح بالاتر استفاده کنید. سه سبک برای انتخاب وجود دارد: هنر، عکس، و طراحی. همچنین اگر میخواهید مدل تصمیم بگیرد، میتوانید گزینه «هیچ» را انتخاب کنید.
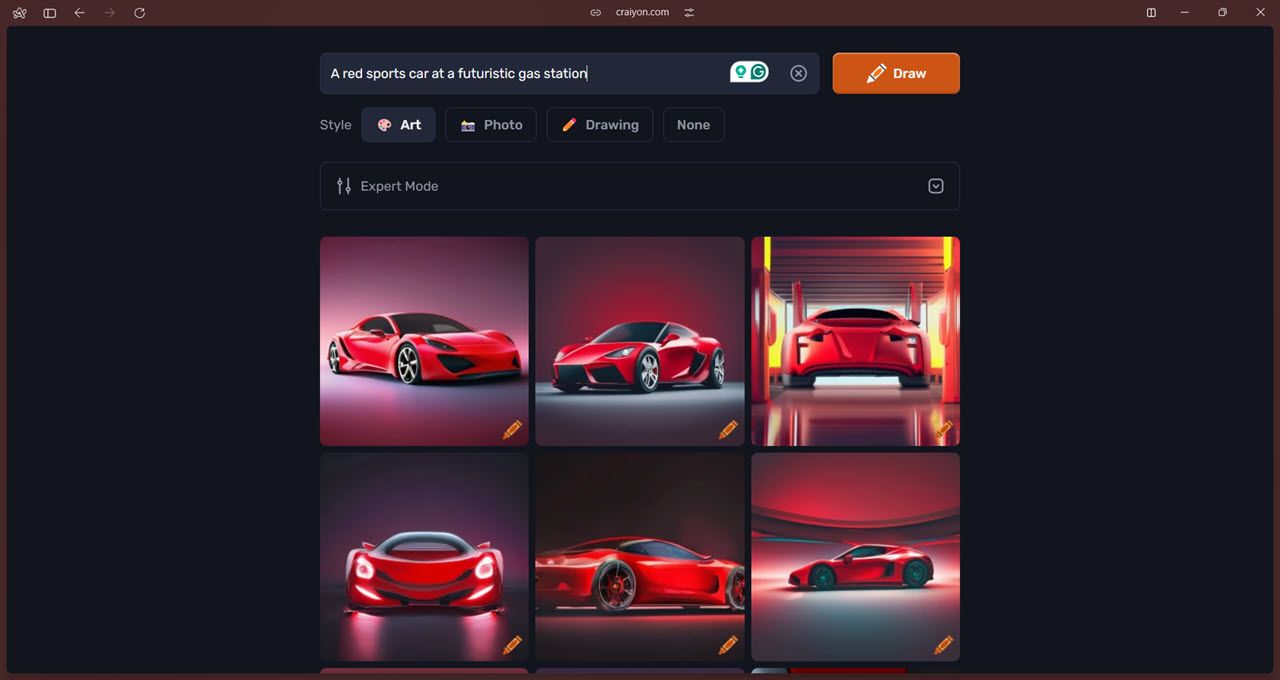
علاوه بر این، “حالت متخصص” به شما امکان می دهد کلمات منفی را اضافه کنید، که به مدل می گوید از موارد خاص اجتناب کند. همچنین یک ویژگی پیشبینی سریع وجود دارد که از ChatGPT برای کمک به کاربران برای نوشتن بهترین و دقیقترین درخواستهای ممکن استفاده میکند. در نهایت، ویژگیهای حذف پسزمینه مبتنی بر هوش مصنوعی میتواند به شما در صرفهجویی در زمان و تلاش برای برش پسزمینه از تصاویر کمک کند.
و این در مورد تمام کارهایی است که کرایون انجام می دهد. این پیچیدهترین مدل تولید تصویر هوش مصنوعی نیست، اما اگر چیزی جزئی یا واقعی نمیخواهید، بهعنوان یک مدل پایه خوب عمل میکند.
استفاده از این مدل رایگان است، اما کاربران رایگان به 9 تصویر رایگان در یک زمان در یک دقیقه محدود میشوند. میتوانید در ردیفهای پشتیبان یا حرفهای آنها (به ترتیب با قیمت ۵ و ۲۰ دلار در ماه و صورتحساب سالانه) مشترک شوید تا بدون تبلیغات یا واترمارک، تولید سریعتر و گزینهای برای خصوصی نگهداشتن تصاویر تولید شده خود را دریافت کنید. یک ردیف اشتراک سفارشی همچنین به مدل های سفارشی، ادغام، پشتیبانی اختصاصی و سرورهای خصوصی اجازه می دهد.
2 انتشار پایدار 1.5
Stable Diffusion شاید یکی از محبوب ترین مدل های متن-به-تصویر منبع باز باشد. همچنین مدل های دیگر، از جمله سه مولد تصویر که در زیر ذکر شده است را تامین می کند. در سال 2022 منتشر شد و از آن زمان تاکنون اجراهای زیادی داشته است.
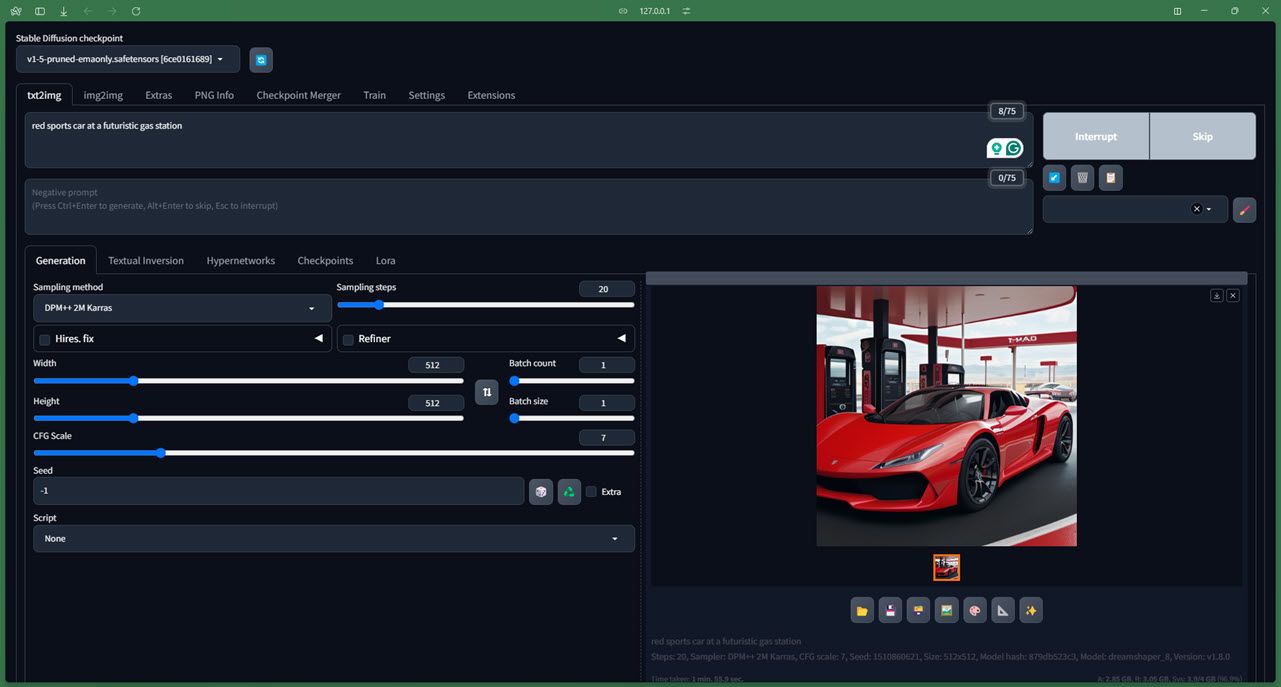
من از جزئیات فنی بیش از حد در مورد نحوه کار مدل صرف نظر می کنم (که می توانید مخزن رسمی Github آنها را بررسی کنید)، اما نصب این مدل حتی برای مبتدیان کاملاً آسان است و تا زمانی که یک GPU اختصاصی با آن دارید به خوبی کار می کند. حداقل 4 گیگابایت حافظه همچنین میتوانید به Stable Diffusion بهصورت آنلاین دسترسی داشته باشید، و اگر میخواهید Stable Diffusion را در مک اجرا کنید، به شما اطلاع دادهایم.
چندین نقطه بازرسی (آنها را نسخه در نظر بگیرید) برای استفاده برای انتشار پایدار وجود دارد. در حالی که ما نسخه 1.5 را آزمایش کردیم، نسخه 2.1 نیز در حال توسعه فعال است و دقیق تر است.

اجرای مدل نیز نسبتاً آسان است. ما آن را با رابط کاربری وب AUTOMATIC1111 Stable Diffusion آزمایش کردیم و همه کنترل ها و پارامترها به خوبی کار می کنند. همچنین به لطف پایگاه داده LAION-5B که مدل بر روی آن آموزش دیده است، کاملاً ضد NSFW است (اگرچه بی نقص نیست، توجه داشته باشید). در حالی که زمان تولید بر اساس سختافزار شما متفاوت است، میتوانید انتظار داشته باشید که تصاویرتان حتی با اعلانهای اولیه دقیق و واقعی باشند.
3 DreamShaper
DreamShaper یک مدل تولید تصویر بر اساس Stable Diffusion است. این به عنوان یک جایگزین متن باز برای MidJourney در نظر گرفته شده بود و بر روی فوتورئالیسم در تصاویر تولید شده تمرکز دارد، اگرچه می تواند با چند ترفند به خوبی سبک های انیمیشن و نقاشی را مدیریت کند.
این مدل نسبت به Stable Diffusion توانایی بیشتری دارد و به کاربران اجازه میدهد آزادی بیشتری در خروجی نهایی داشته باشند، از بهبود رعد و برق گرفته تا محدودیتهای ضعیفتر NSFW. اجرای این مدل نیز آسان است، با یک نسخه قابل دانلود و از پیش آموزش داده شده به صورت آنلاین برای دسترسی محلی و میزبانی از وب سایت ها، از جمله Sinkin.ai، RandomSeed و Mage.space (نیاز به اشتراک اولیه) که به شما امکان می دهد مدل را با شتاب پردازنده گرافیکی
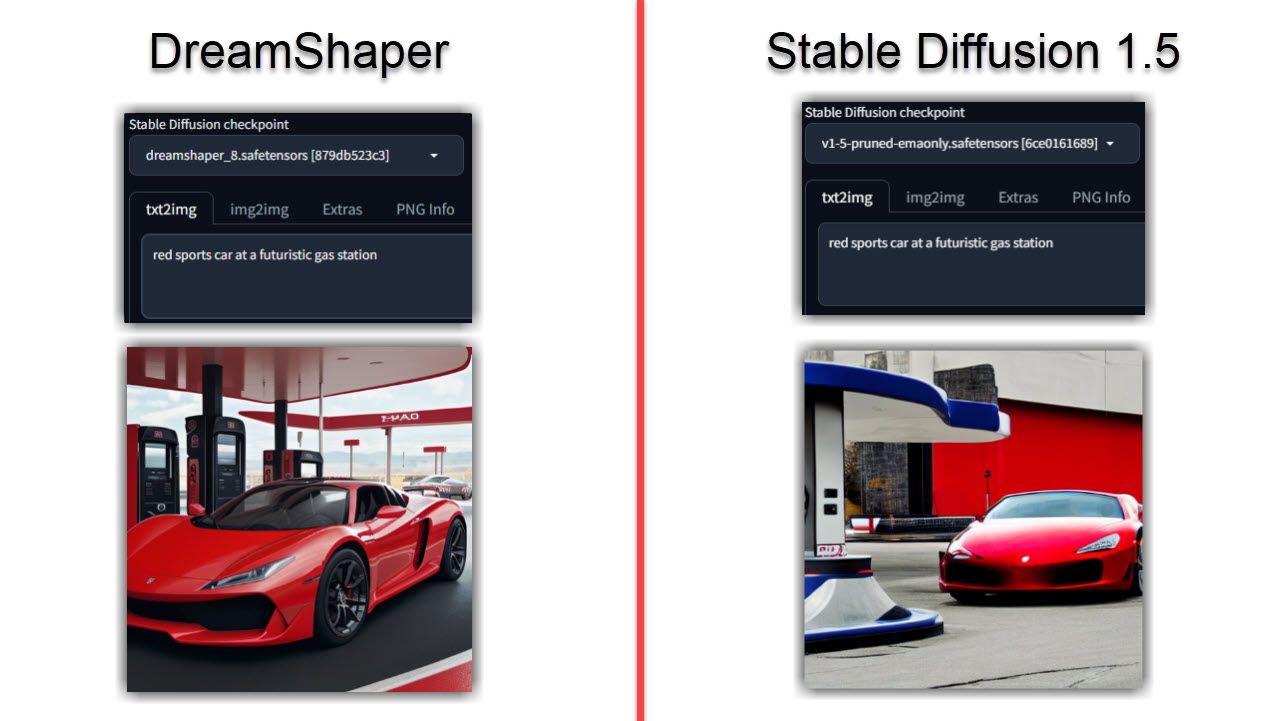
همانطور که احتمالاً می توانید حدس بزنید، تصاویر تولید شده توسط DreamShaper در مقایسه با Stable Diffusion واقعی تر به نظر می رسند. حتی اگر همان فرمان را روی هر دو مدل اجرا کنید، مدل DreamShaper احتمالاً واقعیتر، دقیقتر و روشنتر خواهد بود.
این امر به ویژه برای پرتره ها یا شخصیت ها صادق است، چیزی که من متوجه شدم Stable Diffusion در مقایسه با همان فرمان فاقد آن است. اگر تصاویر شما بیش از حد واقعی هستند، در اینجا چهار راه برای شناسایی تصویر تولید شده توسط هوش مصنوعی وجود دارد.
برای اجرای مدل نیز به رایانه شخصی غول پیکر نیاز ندارید. GTX 1650Ti من با 4 گیگابایت VRAM این مدل را به خوبی اجرا کرد. زمان تولید کمی طولانی تر بود، اما به نظر نمی رسید بر خروجی واقعی تأثیر بگذارد. گفتنی است، ممکن است برای اجرای DreamShaper XL که بر اساس مدل Stable Diffusion XL است، به پردازندههای گرافیکی با VRAM بیشتری نیاز داشته باشید.
4 InvokeAI
Invoke AI یکی دیگر از مدل های تولید تصویر مبتنی بر هوش مصنوعی است که بر اساس Stable Diffusion، با نسخه XL مبتنی بر Stable Diffusion XL است. همچنین دارای وب و رابط کاربری خط فرمان خود است، به این معنی که شما مجبور نخواهید بود با چیزهایی مانند رابط کاربری وب Stable Diffusion از حلقه ها استفاده کنید.
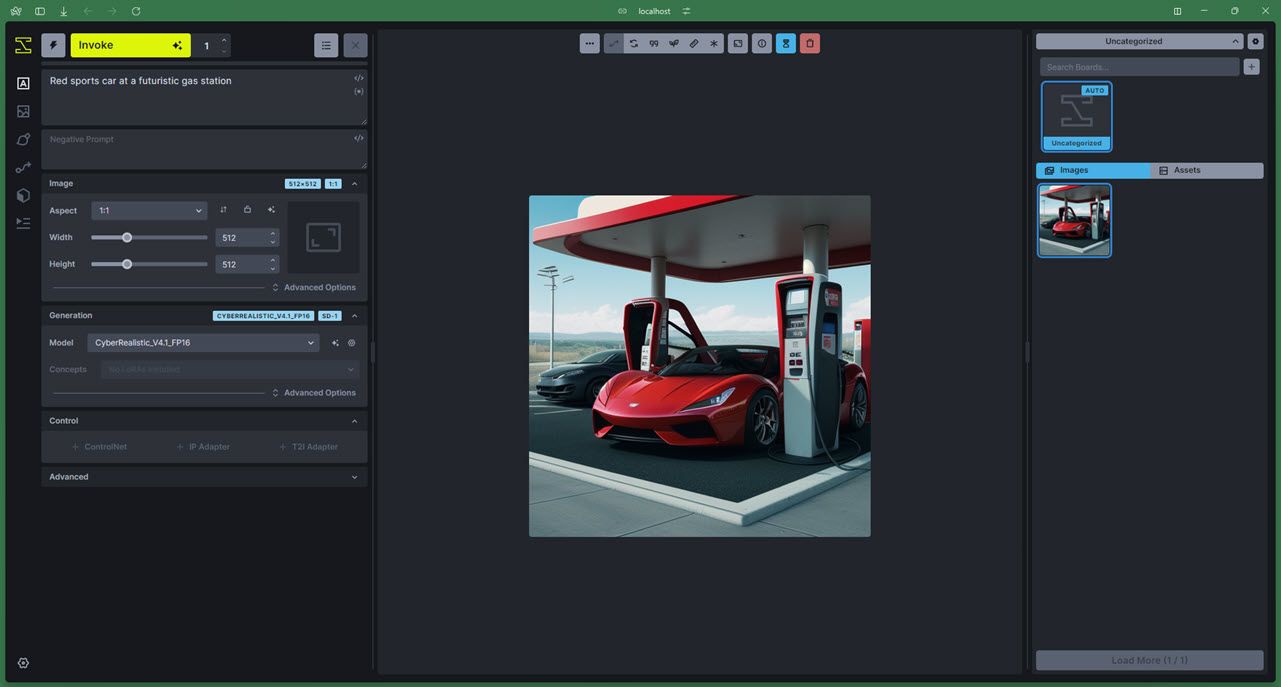
این مدل بر روی اجازه دادن به کاربران برای ایجاد تصاویر بر اساس مالکیت معنوی خود با گردش کار سفارشی تمرکز دارد. InvokeAI یکی از بهترین مدل های تولید تصویر AI منبع باز برای آموزش مدل های سفارشی و کار با مالکیت معنوی است.
مخزن رسمی Github آن دو روش نصب را فهرست می کند: نصب از طریق نصب کننده InvokeAI یا استفاده از PyPI اگر با ترمینال و پایتون راحت هستید و به کنترل بیشتری بر روی بسته های نصب شده با مدل نیاز دارید.
با این حال، کنترل اضافی چند محدودیت را به همراه دارد، به ویژه الزامات سخت افزاری سخت تر. InvokeAI یک GPU اختصاصی با حداقل 4 گیگابایت حافظه را توصیه می کند که برای اجرای نسخه XL شش تا هشت گیگابایت توصیه می شود. الزامات VRAM برای هر دو پردازنده گرافیکی AMD و Nvidia اعمال می شود. همچنین برای مدل، وابستگی های آن و پایتون به حداقل 12 گیگابایت رم و 12 گیگابایت فضای دیسک رایگان نیاز دارید.

در حالی که اسناد، پردازندههای گرافیکی GTX سری 10 و سری 16 انویدیا را به دلیل کمبود حافظه ویدیویی توصیه نمیکنند، نصبکننده ارائهشده به خوبی اجرا شد. در حالی که مسافت پیموده شده شما ممکن است متفاوت باشد، اگر از یک پردازنده گرافیکی پایینتر استفاده میکنید، انتظار داشته باشید مدت بیشتری منتظر بمانید تا پیامهایتان را به تصویر تبدیل کنید. در نهایت، اگر از ویندوز استفاده میکنید، فقط میتوانید از GPU Nvidia استفاده کنید، زیرا در حال حاضر هیچ پشتیبانی از پردازندههای گرافیکی AMD وجود ندارد.
برای بخش تولید تصویر، مدل بیشتر به سمت سبکهای هنری متمایل است تا فوتورئالیسم. البته، میتوانید مدل را روی مجموعه دادههای خود آموزش دهید و از آن بخواهید تصاویری نزدیکتر به آنچه میخواهید تولید کند، حتی اگر شامل تصاویر واقعگرایانه باشد، بهخصوص اگر در طراحی محصول، معماری یا فضاهای خردهفروشی کار میکنید. با این حال، یک نکته مهم که باید در نظر داشته باشید این است که InvokeAI در درجه اول یک موتور تولید تصویر است، به این معنی که احتمالاً باید از مدل های خود برای بهترین نتایج (که به راحتی از طریق مدیر مدل ارائه شده در رابط وب پیدا می شود) به عنوان پیش فرض استفاده کنید. مدل کاملاً شبیه به خود Stable Diffusion است.
5 سفر باز
Openjourney یک مدل رایگان و منبع باز تولید تصویر هوش مصنوعی است که دوباره بر اساس انتشار پایدار است. اگر تعجب می کنید که چرا این مدل Openjourney نام دارد، به این دلیل است که بر روی تصاویر Midjourney آموزش داده شده است و می تواند سبک خود را در تصاویری که تولید می کند تقلید کند.
PromptHero، شرکت پشتیبان Openjourney، به شما امکان می دهد مدل را در کنار مدل های دیگر، از جمله Stable Diffusion (نسخه های 1.5 و 2)، DreamShaper و Realistic Vision آزمایش کنید. هنگام ثبت نام، 25 اعتبار رایگان (یک اعتبار برای هر تصویر ایجاد شده) دریافت می کنید، پس از آن باید در ردیف اشتراک Pro آنها مشترک شوید که هزینه آن 9 دلار در ماه است و به شما امکان دسترسی به 300 اعتبار هر ماه با سایر ویژگی های انحصاری را می دهد.

با این حال، اگر می خواهید آن را به صورت محلی و رایگان اجرا کنید، می توانید فایل مدل را از HuggingFace دانلود کرده و با استفاده از رابط کاربری وب Stable Diffusion اجرا کنید. Openjourney همچنین دومین مدل تولید تصویر هوش مصنوعی در HuggingFace است که پس از Stable Diffusion قرار دارد.
Openjourney هیچ نیاز سخت افزاری خاصی را برای اجرای مدل به صورت محلی در وب سایت خود فهرست نمی کند، اما می توانید نیازهای سخت افزاری مشابه Stable Diffusion را انتظار داشته باشید. این به معنای یک GPU اختصاصی با 4 گیگابایت VRAM، 16 گیگابایت رم و حدود 12 تا 15 گیگابایت فضای خالی در رایانه شما است تا مدل و وابستگی های آن را ذخیره کنید.

تصاویر تولید شده توسط Openjourney تمایل دارند بین فوتورئالیسم و هنر تعادل برقرار کنند، مگر اینکه طور دیگری مشخص شده باشد. اگر به دنبال یک مدل همه جانبه هستید و ظاهر و احساس Midjourney را بدون پرداخت هزینه اشتراک ترجیح می دهید، Openjourney یکی از بهترین گزینه ها است.