
فراتر از مایکروسافت اکسل بروید و یاد بگیرید که چگونه تبلت های محوری را با پایتون و فقط چند خط کد ایجاد کنید.
جداول محوری همچنان یکی از معتبرترین و پرکاربردترین ابزارها در MS Excel هستند. چه یک تحلیلگر داده، مهندس داده یا صرفاً یک کاربر معمولی باشید، به احتمال زیاد در حال حاضر نقطه نرمی برای MS Excel دارید.
با این وجود، دامنه رو به افزایشی برای تکرار ابزارها و ابزارهای MS Excel، به ویژه در پایتون وجود دارد. آیا می دانستید که می توانید جداول محوری گسترده ای را در DataFrames پایتون با چند خط کد ایجاد کنید؟
بله، درست است. اگر مجذوب هستید، در اینجا نحوه انجام این کار آمده است.
پیش نیاز برای ایجاد Pivot Tables
مانند هر زبان برنامه نویسی دیگری، حتی پایتون نیز به شما نیاز دارد تا قبل از اینکه بتوانید به کدنویسی برسید، چند پیش نیاز را برآورده کنید.
برای بدست آوردن بهینه ترین تجربه در هنگام ایجاد اولین جدول محوری خود در پایتون، در اینجا چیزی است که نیاز دارید:
- Python IDE: اکثر کدهای پایتون دارای یک محیط توسعه یکپارچه (IDE) از قبل روی سیستم خود هستند. چندین IDE سازگار با پایتون در بازار وجود دارد، از جمله Jupyter Notebook، Spyder، PyCharm و بسیاری دیگر.
- داده های نمونه: برای مثال، در اینجا یک مجموعه داده نمونه وجود دارد که می توانید روی آن کار کنید. از طرف دیگر، می توانید این کدها را مستقیماً روی داده های زنده خود تغییر دهید.
لینک نمونه داده:Sample Superstore
واردات کتابخانه های ضروری
از آنجایی که پایتون بر روی مفهوم کتابخانه های شخص ثالث کار می کند، باید کتابخانه Pandas را برای ایجاد محورها وارد کنید.
می توانید از پانداها برای وارد کردن یک فایل اکسل به پایتون و ذخیره داده ها در یک DataFrame استفاده کنید. برای وارد کردن پانداها، از دستور import به روش زیر استفاده کنید:
import pandas as pd
نحوه ایجاد Pivot در پایتون
از آنجایی که کتابخانه اکنون در دسترس است، باید فایل اکسل را به پایتون وارد کنید، که پایه ای برای ایجاد و آزمایش پیوت ها در پایتون است. داده های وارد شده را در یک DataFrame با کد زیر ذخیره کنید:
# Create a new DataFrame
# replace with your own path here
path = "C://Users//user/OneDrive//Desktop//"
# you can define the filename here
file = "Sample - Superstore.xls"
df = pd.read_excel(path + file)
df.head()
جایی که:
- df: نام متغیر برای ذخیره داده های DataFrame
- pd: کتابخانه نام مستعار پانداها
- read_excel(): تابع Pandas برای خواندن فایل اکسل در پایتون
- مسیر: مکانی که فایل اکسل در آن ذخیره می شود (Sample Superstore)
- فایل: نام فایل برای وارد کردن
- head(): پنج ردیف اول DataFrame را به صورت پیش فرض نمایش می دهد
کد بالا فایل اکسل را به پایتون وارد کرده و داده ها را در یک DataFrame ذخیره می کند. در نهایت، تابع head پنج ردیف اول داده ها را نمایش می دهد.
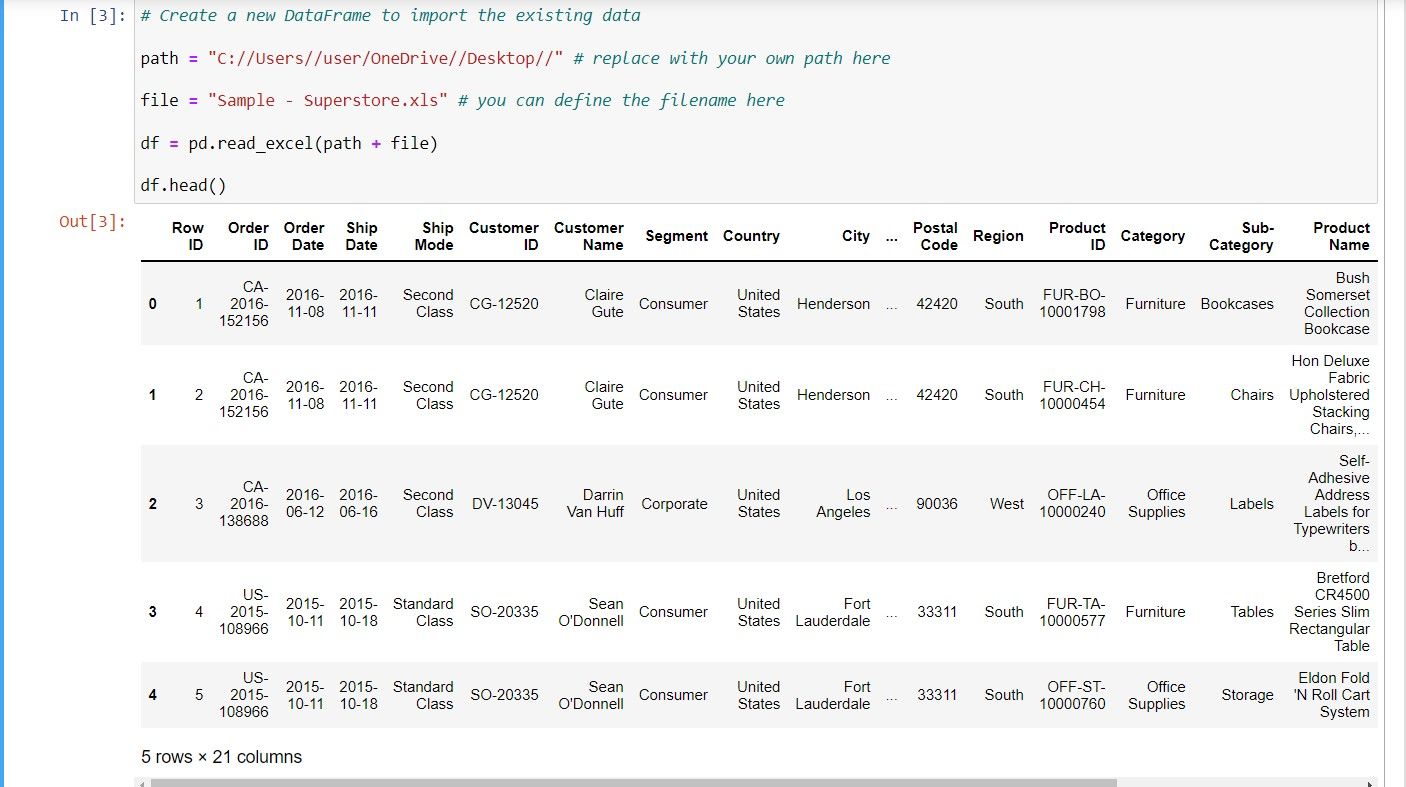
این تابع برای اطمینان از وارد شدن صحیح داده ها به پایتون مفید است.
کدام فیلدهای جدول محوری در پایتون وجود دارد؟
مانند همتای اکسل خود، جدول محوری دارای مجموعه ای از فیلدهای مشابه در پایتون است. در اینجا چند زمینه وجود دارد که باید در مورد آنها بدانید:
- Data: فیلد داده به داده های ذخیره شده در یک DataFrame پایتون اشاره دارد
- مقادیر: داده های ستونی مورد استفاده در یک محور
- Index: یک ستون(های) شاخص برای گروه بندی داده ها
- ستون ها: ستون ها به جمع آوری داده های موجود در یک DataFrame کمک می کنند
هدف پشت با استفاده از تابع شاخص
از آنجایی که تابع شاخص عنصر اصلی جدول محوری است، طرح اولیه داده ها را برمی گرداند. به عبارت دیگر، می توانید داده های خود را با تابع شاخص گروه بندی کنید.
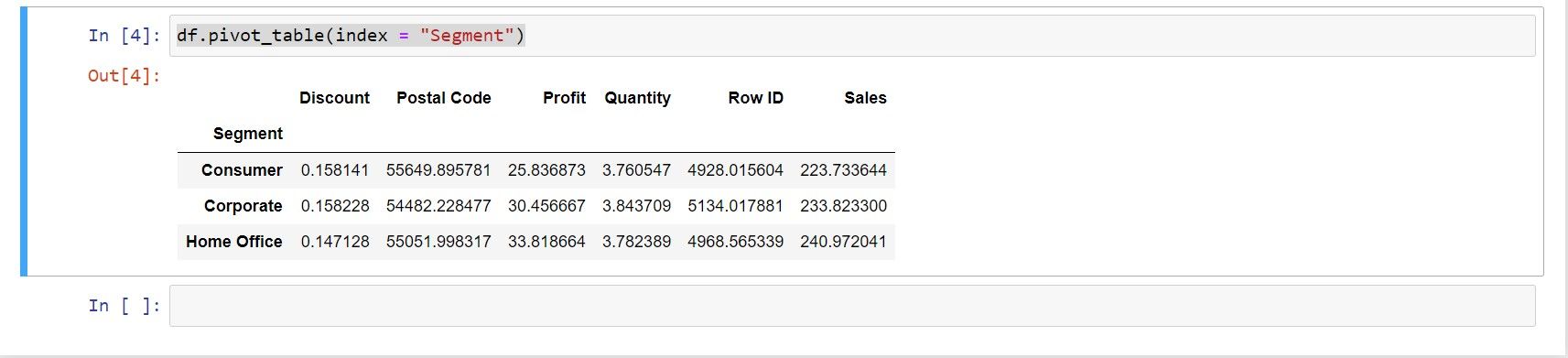
فرض کنید می خواهید مقادیری را برای محصولات فهرست شده در ستون Segment مشاهده کنید. شما می توانید با تعریف ستون تعیین شده به عنوان مقدار شاخص، یک مجموع از پیش تعریف شده (مقدار متوسط) در پایتون را محاسبه کنید.
df.pivot_table(index = "Segment")
جایی که:
- df: DataFrame حاوی داده ها
- pivot_table: تابع جدول محوری در پایتون
- index: تابع داخلی برای تعریف ستون به عنوان شاخص
- بخش: ستونی برای استفاده به عنوان مقدار شاخص
نام متغیرهای پایتون به حروف کوچک و بزرگ حساس هستند، بنابراین از تغییر نام متغیرهای از پیش تعریف شده فهرست شده در این راهنما خودداری کنید.
نحوه استفاده از مقادیر چند شاخصی
هنگامی که می خواهید از چندین ستون فهرست استفاده کنید، می توانید نام ستون ها را در یک لیست در تابع شاخص تعریف کنید. تنها کاری که باید انجام دهید این است که نام ستون ها را در مجموعه ای از پرانتز ([ ]) مانند شکل زیر مشخص کنید:
df.pivot_table(index = ["Category", "Sub-Category"])
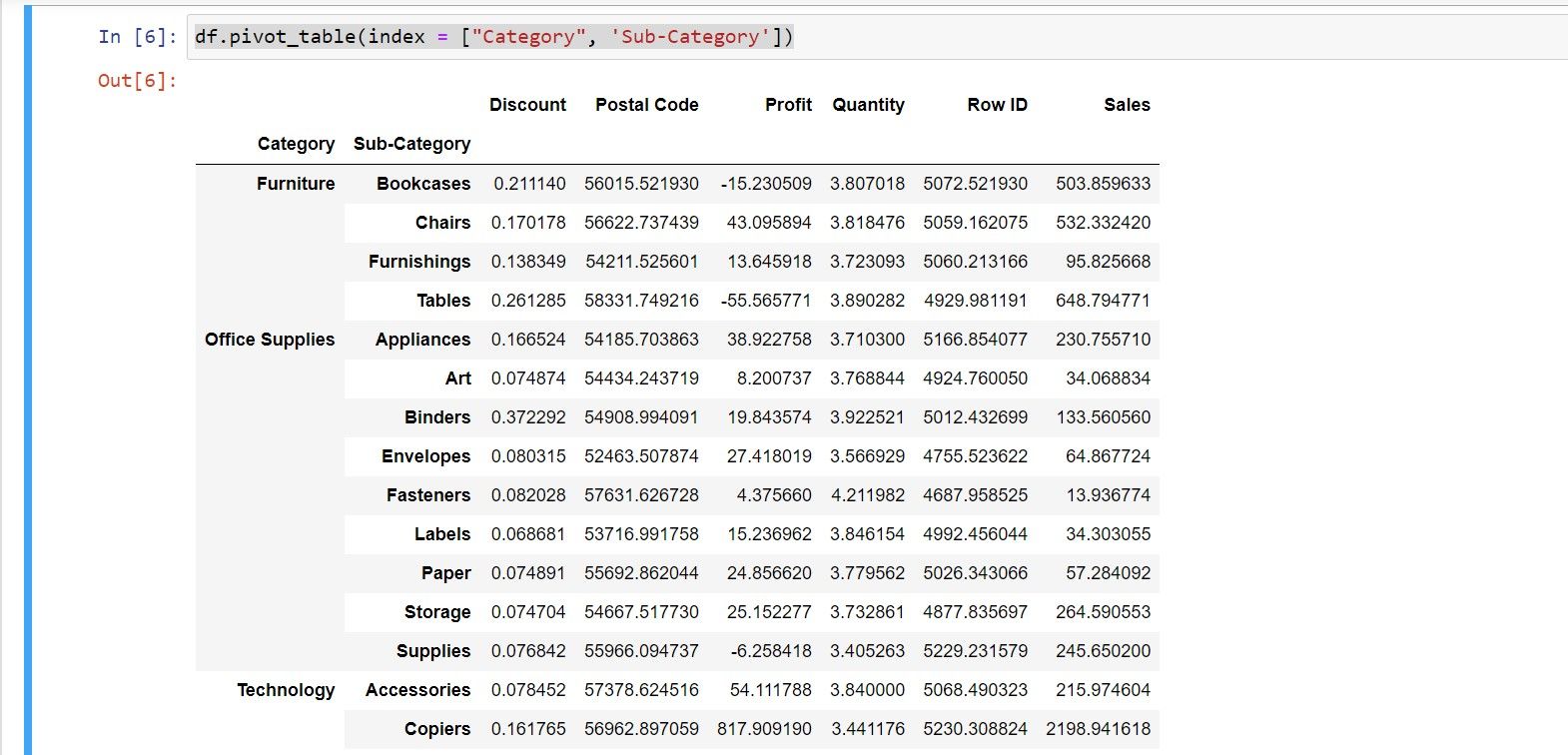
تابع pivot ستون شاخص را در خروجی فرورفتگی می کند. پایتون میانگین تمام مقادیر عددی را در برابر هر مقدار شاخص نمایش می دهد.
یاد بگیرید که مقادیر را در خروجی محدود کنید
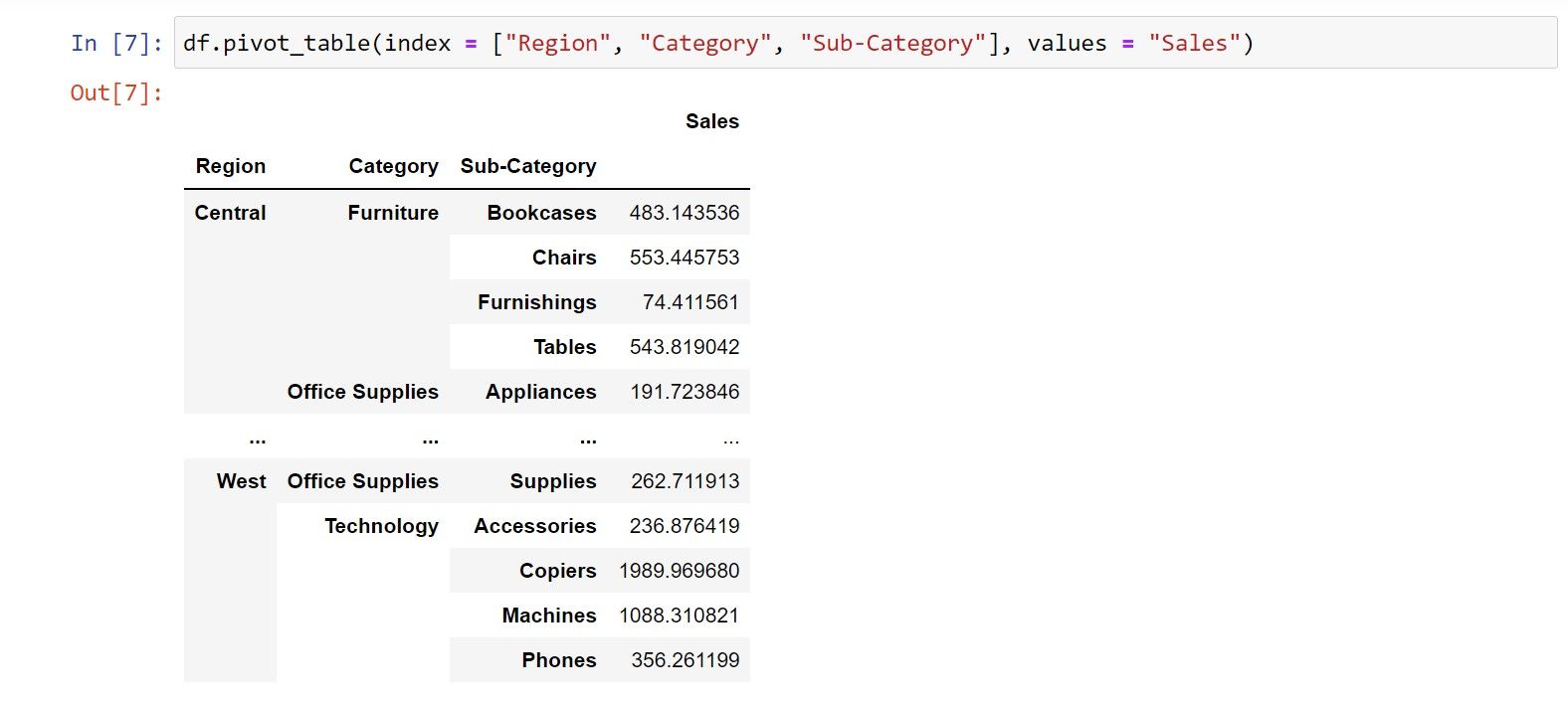
از آنجایی که پایتون تمام ستونهای عددی را بهطور پیشفرض انتخاب میکند، میتوانید مقادیر را برای تغییر نتایج نشاندادهشده در خروجی نهایی محدود کنید. از تابع مقادیر برای تعریف ستون هایی که می خواهید ببینید استفاده کنید.
df.pivot_table(index = ["Region", "Category", "Sub-Category"], values = "Sales")
در خروجی نهایی، سه ستون شاخص وجود خواهد داشت و مقادیر میانگین برای ستون فروش در مقابل هر عنصر قرار میگیرد.
تعریف توابع مجموع در جدول محوری
وقتی نمی خواهید مقادیر میانگین را به طور پیش فرض محاسبه کنید چه اتفاقی می افتد؟ جدول محوری دارای بسیاری از عملکردهای دیگر است که فراتر از محاسبه میانگین ساده است.
در اینجا نحوه نوشتن کد آمده است:
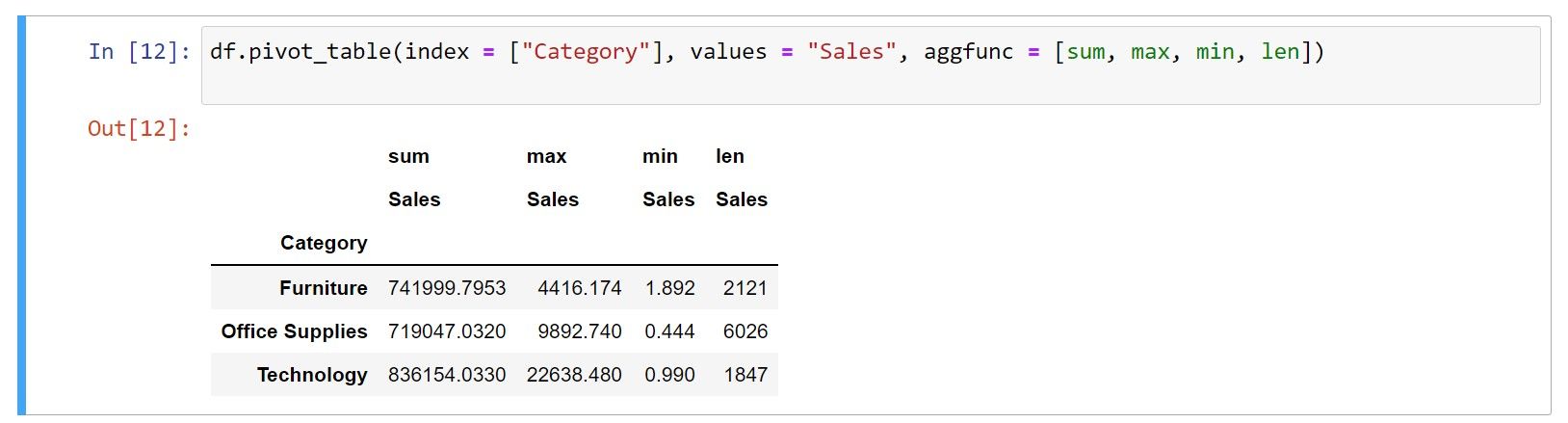
df.pivot_table(index = ["Category"], values = "Sales", aggfunc = [sum, max, min, len])
جایی که:
- sum: مجموع مقادیر را محاسبه می کند
- max: حداکثر مقدار را محاسبه می کند
- min: حداکثر مقدار را محاسبه می کند
- len: تعداد مقادیر را محاسبه می کند
همچنین می توانید هر یک از این توابع را در خطوط کد جداگانه تعریف کنید.
چگونه کل کل را به جدول محوری اضافه کنیم
هیچ دارایی داده ای بدون مجموع کل کامل نیست. برای محاسبه و نمایش مجموع کل در هر ستون داده، از تابع margins و margins_name استفاده کنید.
df.pivot_table(index = ["Category"], values = "Sales", aggfunc = [sum, max, min, len], margins=True, margins_name='Grand Totals')
جایی که:
- حاشیه: تابعی برای محاسبه کل کل
- margins_name: نام دسته را در ستون نمایه مشخص کنید (به عنوان مثال، کل کل)
کد نهایی را تغییر دهید و از آن استفاده کنید
در اینجا خلاصه کد نهایی است:
import pandas as pd
# replace with your own path here
path = "C://Users//user/OneDrive//Desktop//"
# you can define the filename here
file = "Sample - Superstore.xls"
df = pd.read_excel(path + file)
df.pivot_table(index = ["Region", "Category", "Sub-Category"], values = "Sales",
aggfunc = [sum, max, min, len],
margins=True,
margins_name='Grand Totals')
ایجاد Pivot Tables در پایتون
وقتی از جداول Pivot استفاده می کنید، گزینه ها به سادگی بی پایان هستند. پایتون به شما این امکان را میدهد تا به راحتی آرایههای دادهای گسترده را بدون نگرانی در مورد اختلاف دادهها و تاخیرهای سیستم مدیریت کنید.
از آنجایی که عملکردهای پایتون فقط به فشرده سازی داده ها در محورها محدود نمی شود، می توانید چندین کتاب کار و برگه اکسل را ترکیب کنید، در حالی که یک سری توابع مرتبط را با پایتون انجام دهید.
با پایتون، همیشه چیز جدیدی در افق وجود دارد.