
آیا درست است که ادعا کنیم کتابخانه جدید Polars در معیارهای متعدد از پانداها پیشی گرفته است یا کتابخانه پانداها همچنان انتخاب غالب است؟
در حین انجام وظایف تجزیه و تحلیل داده ها، به احتمال زیاد با پانداها روبرو شده اید. این کتابخانه برای مدت طولانی غالب ترین کتابخانه در تجزیه و تحلیل داده ها بوده است. از طرف دیگر Polars یک کتابخانه نسبتاً جدید است که عملکرد و کارایی حافظه بالایی دارد. اما، کدام یک بهتر است؟
در اینجا، مقایسه ای از عملکرد پانداها و قطبی ها را در طیف وسیعی از کارهای رایج دستکاری داده ها مشاهده خواهید کرد.
اندازهگیری عملکرد: معیارها و مجموعه دادههای معیار
این مقایسه توانایی کتابخانههای پانداها و قطبها را در دستکاری مجموعه دادههای فروش جمعه سیاه از Kaggle در نظر میگیرد. این مجموعه داده شامل 550068 ردیف داده است. این شامل اطلاعاتی در مورد جمعیت شناسی مشتری، تاریخچه خرید و جزئیات محصول است.
برای اطمینان از اندازهگیریهای عملکرد منصفانه، مقایسه از زمان اجرا بهعنوان معیار عملکرد استاندارد در هر کار استفاده میکند. پلتفرم اجرای کد برای هر کار مقایسه Google Colab خواهد بود.
کد منبع کاملی که کتابخانههای پانداها و قطبها را با هم مقایسه میکند در یک مخزن GitHub موجود است.
خواندن داده ها از یک فایل CSV
این کار زمان لازم برای خواندن دادهها از مجموعه دادههای فروش جمعه سیاه را برای هر کتابخانه مقایسه میکند. مجموعه داده در قالب CSV است. پانداها و قطبی ها عملکرد مشابهی را برای این کار ارائه می دهند.
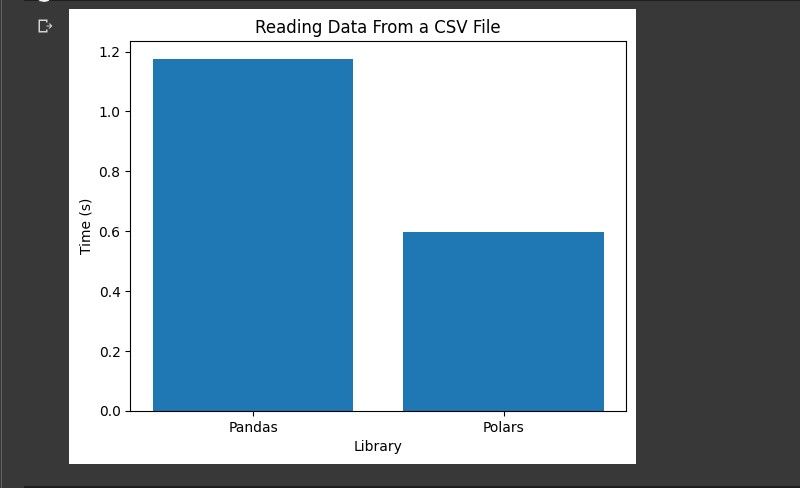
پانداها دو برابر زمانی را که پولارها برای خواندن داده ها در مجموعه داده فروش جمعه سیاه صرف می کنند، صرف می کنند.
انتخاب ستون ها
این وظیفه مدت زمانی را که برای هر کتابخانه لازم است تا ستون ها را از مجموعه داده انتخاب کند اندازه گیری می کند. این شامل انتخاب ستون User_ID و Purchase است.
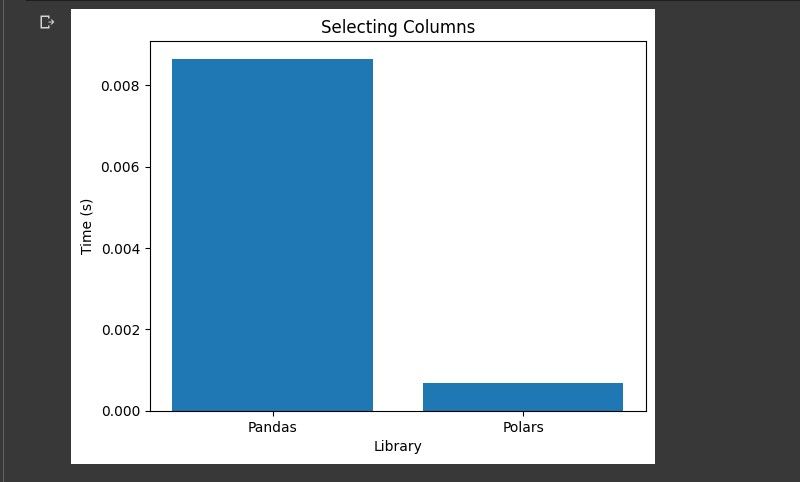
قطب ها در مقایسه با پانداها زمان بسیار کمتری را برای انتخاب ستون ها از مجموعه داده صرف می کنند.
فیلتر کردن ردیف ها
این کار عملکرد هر کتابخانه را در فیلتر کردن ردیف هایی که در آن ستون جنسیت F از مجموعه داده است، مقایسه می کند.
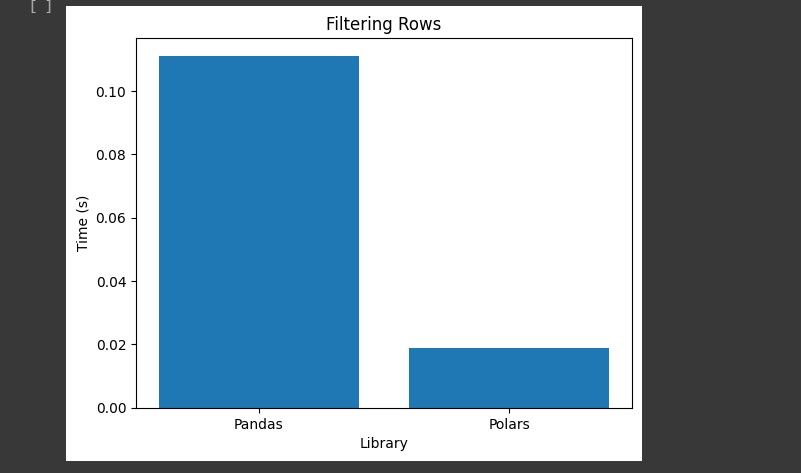
قطبی ها در مقایسه با پانداها زمان بسیار کوتاهی برای فیلتر کردن ردیف ها نیاز دارند.
گروه بندی و جمع آوری داده ها
این کار شامل گروه بندی داده ها بر اساس یک یا چند ستون است. سپس، انجام برخی از توابع تجمع بر روی گروه ها. مدت زمانی را که هر کتابخانه برای گروه بندی داده ها بر اساس ستون جنسیت نیاز دارد و میانگین مقدار خرید برای هر گروه را محاسبه می کند، اندازه گیری می کند.
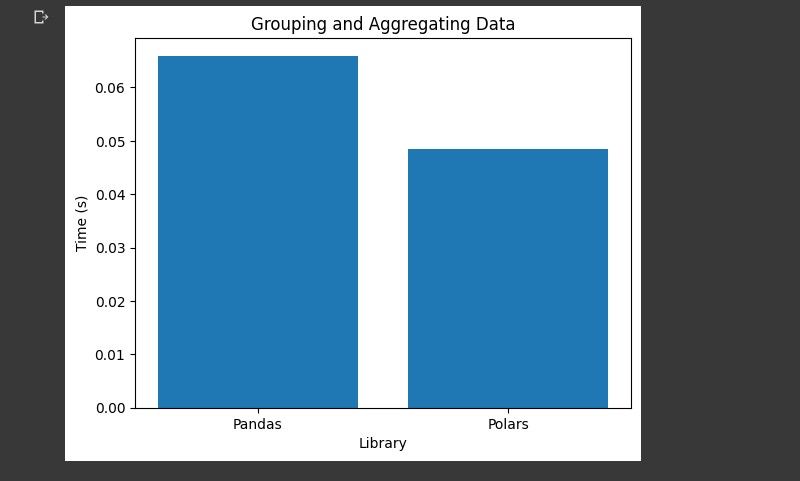
باز هم قطبی ها از پانداها بهتر عمل می کنند. اما حاشیه به اندازه فیلتر کردن ردیف ها زیاد نیست.
اعمال توابع به داده ها
این کار شامل اعمال یک تابع در یک یا چند ستون است. زمان ضرب کردن ستون خرید در 2 را برای هر کتابخانه اندازه گیری می کند.
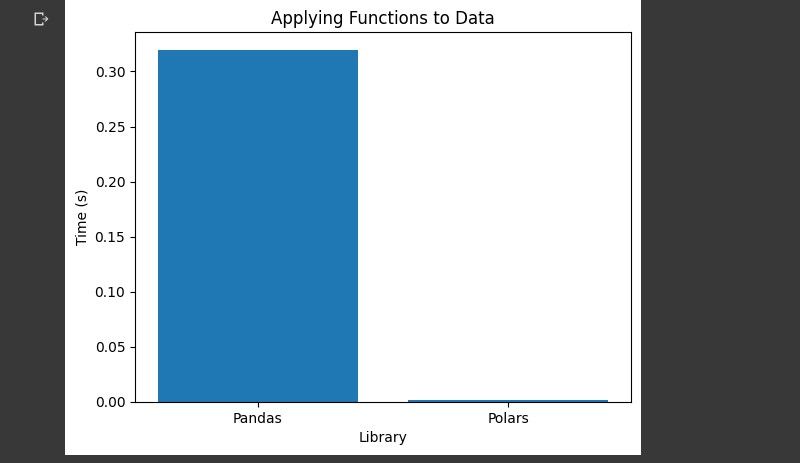
شما به سختی می توانید نوار Polars را ببینید. قطبی ها بار دیگر از پانداها پیشی گرفتند.
ادغام داده ها
این وظیفه شامل ادغام دو یا چند DataFrame بر اساس وجود یک یا چند ستون مشترک است. زمان لازم برای ادغام ستونهای User_ID و Purchase را از دو DataFrame جداگانه برای هر کتابخانه اندازهگیری میکند.
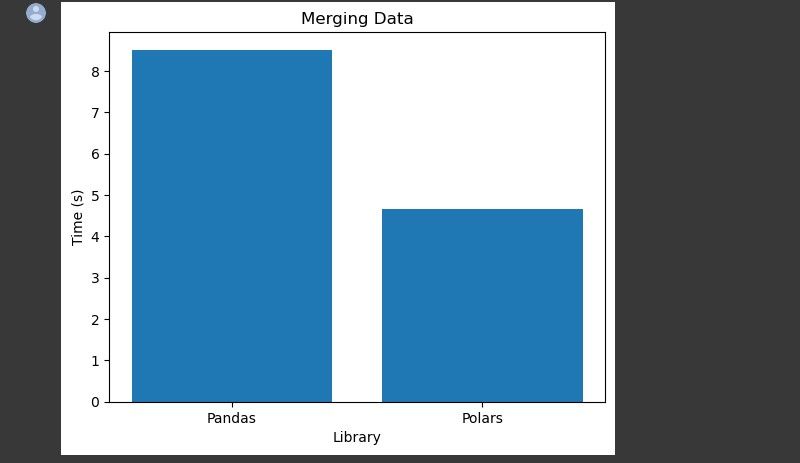
هر دو کتابخانه مدتی طول می کشد تا این کار را انجام دهند. اما Polars تقریباً نیمی از زمانی را که پانداها برای ادغام داده ها صرف می کنند طول می کشد.
چرا Polars می تواند از پانداها پیشی بگیرد؟
در تمام کارهای دستکاری داده های بالا، قطب ها از پانداها بهتر عمل می کنند. دلایل متعددی وجود دارد که چرا قطب ها ممکن است در زمان اجرا بهتر از پانداها عمل کنند.
- بهینه سازی حافظه: Polars از Rust، یک زبان برنامه نویسی سیستمی استفاده می کند که استفاده از حافظه را بهینه می کند. این به Polars اجازه می دهد تا زمانی را که برای تخصیص و تخصیص حافظه صرف می کند به حداقل برساند. این باعث می شود زمان اجرا سریعتر شود.
- عملیات SIMD (Single Instruction Multiple Data): Polars از عملیات SIMD برای انجام محاسبات روی داده ها استفاده می کند. این بدان معنی است که می تواند از یک دستورالعمل برای انجام یک عملیات مشابه بر روی چندین عنصر داده به طور همزمان استفاده کند. این به قطبی اجازه می دهد تا عملیات را بسیار سریعتر از پانداها انجام دهد که از رویکرد تک رشته ای استفاده می کنند.
- ارزیابی تنبلی: Polars از ارزیابی تنبلی برای به تاخیر انداختن اجرای عملیات تا زمانی که به آنها نیاز داشته باشد استفاده می کند. این مقدار زمانی را که Polars صرف عملیات غیر ضروری می کند کاهش می دهد و عملکرد را بهبود می بخشد.
مهارت های علم داده خود را گسترش دهید
کتابخانه های پایتون زیادی وجود دارد که می توانند در علم داده به شما کمک کنند. پانداها و قطبی ها فقط کسری کوچک هستند. برای بهبود عملکرد برنامه خود، باید با کتابخانه های علوم داده بیشتری آشنا شوید. این به شما کمک می کند تا مقایسه کنید و انتخاب کنید که کدام کتابخانه مناسب مورد استفاده شما است.