
MapReduce یک روش ثابت برای موازی سازی پرس و جوهای داده است، اما آیا این جایگزین می تواند مزایای بیشتری را ارائه دهد؟
نکات کلیدی
- MapReduce و خط لوله تجمع دو روش برای پردازش داده های پیچیده در MongoDB هستند. چارچوب تجمیع جدیدتر و کارآمدتر است.
- MapReduce شامل تعیین نقشه جداگانه و توابع کاهش با استفاده از جاوا اسکریپت است، در حالی که خط لوله تجمع از عملگرهای داخلی MongoDB استفاده می کند.
- خط لوله تجمیع توسط MongoDB برای عملکرد بهتر توصیه می شود، اما MapReduce انعطاف پذیری بیشتری ارائه می دهد و برای سیستم های فایل توزیع شده مانند Hadoop مناسب است.
MapReduce و خط لوله تجمع دو روشی هستند که می توانید برای مقابله با پردازش داده های پیچیده در MongoDB استفاده کنید. چارچوب تجمیع جدیدتر است و به دلیل کارایی آن شناخته شده است. اما برخی از توسعه دهندگان همچنان ترجیح می دهند به MapReduce پایبند باشند که آن را راحت تر می دانند.
در عمل، شما می خواهید یکی از این روش های پرس و جو پیچیده را انتخاب کنید، زیرا آنها به یک هدف می رسند. اما آنها چگونه کار میکنند؟ تفاوت آنها چگونه است و کدام را باید استفاده کنید؟
نحوه عملکرد MapReduce در MongoDB
MapReduce در MongoDB به شما امکان می دهد محاسبات پیچیده را روی حجم زیادی از داده ها اجرا کنید و نتیجه را در یک بخش جامع تر جمع آوری کنید. روش MapReduce دارای دو عملکرد است: نقشه و کاهش.
در حین کار با MapReduce در MongoDB، نقشه و توابع کاهش را به طور جداگانه با استفاده از جاوا اسکریپت مشخص کرده و هر کدام را در پرس و جوی داخلی mapReduce قرار می دهید.
تابع نقشه ابتدا دادههای دریافتی را به جفتهای کلید-مقدار تقسیم میکند – معمولاً براساس گروهبندی نگاشت شده. این جایی است که شما نحوه گروه بندی داده ها را مشخص می کنید. سپس تابع کاهش، محاسبات سفارشی را روی مقادیر هر گروه داده اجرا می کند و نتیجه را در یک مجموعه جداگانه ذخیره شده در پایگاه داده جمع می کند.
چگونه خط لوله تجمع در MongoDB کار می کند
خط لوله تجمع در MongoDB یک جایگزین بهبود یافته برای MapReduce است. مانند MapReduce، به شما امکان می دهد محاسبات پیچیده و تبدیل داده ها را مستقیماً در داخل پایگاه داده انجام دهید. اما تجمیع نیازی به نوشتن توابع اختصاصی جاوا اسکریپت ندارد که بتواند عملکرد پرس و جو را کاهش دهد.
در عوض، از عملگرهای داخلی MongoDB برای دستکاری، گروه بندی و محاسبه داده ها استفاده می کند. سپس نتایج را پس از هر پرس و جو جمع می کند. بنابراین، خط لوله جمعآوری قابل تنظیمتر است زیرا میتوانید خروجی را همانطور که دوست دارید ساختار دهید.
تفاوت کوئری ها بین MapReduce و Aggregation
فرض کنید می خواهید کل فروش اقلام را بر اساس دسته بندی محصول محاسبه کنید. در مورد MapReduce و aggregation، دسته های محصول به کلید تبدیل می شوند، در حالی که مجموع اقلام زیر هر دسته به مقادیر مربوطه تبدیل می شوند.
نمونه ای از داده های خام را برای بیان مشکل توصیف شده در نظر بگیرید، که به نظر می رسد:
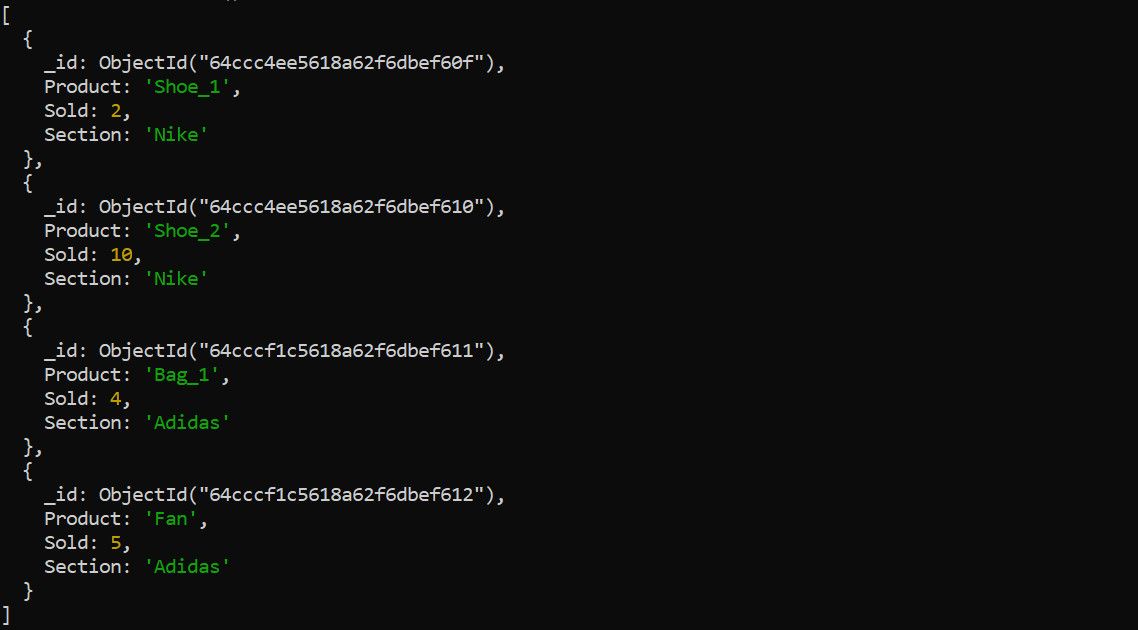
بیایید این سناریوی مشکل را با استفاده از MapReduce و یک خط لوله جمعآوری حل کنیم تا بین کوئریها و روشهای حل مسئله تفاوت قائل شویم.
روش MapReduce
با استفاده از پایتون به عنوان زبان برنامه نویسی پایه، پرس و جو mapReduce سناریوی مشکل که قبلا توضیح داده شده است به صورت زیر است:
import pymongo
client = pymongo.MongoClient(
"mongodb://localhost/"
)
db = client.my_database
sales = db["sales"]
map_function = """
function() {
emit(this.Section, this.Sold);
}
"""
reduce_function = """
function(key, values) {
return Array.sum(values);
}
"""
result = db.command(
"mapReduce",
"sales",
map=map_function,
reduce=reduce_function,
out="section_totals"
)
doc = [doc for doc in db.section_totals.find()]
print(doc)
اگر این را در برابر داده های نمونه اصلی اجرا کنید، خروجی مانند زیر را خواهید دید:
[{
'_id': 'Adidas',
'value': 9.0
},{
'_id': 'Nike',
'value': 12.0
}]
با دقت نگاه کنید، و باید ببینید که نقشه و پردازشگرهای کاهش، توابع جاوا اسکریپت درون متغیرهای پایتون هستند. کد این موارد را به پرس و جو mapReduce ارسال می کند که مجموعه خروجی اختصاصی (section_totals) را مشخص می کند.
استفاده از خط لوله تجمع
علاوه بر ارائه خروجی نرمتر، کوئری خط لوله تجمع مستقیمتر است. در اینجا عملیات قبلی با خط لوله تجمع به نظر می رسد:
import pymongo
client = pymongo.MongoClient("mongodb://localhost/")
db = client.funmi
sales = db["sales"]
pipeline = [
{
"$group": {
"_id": "$Section",
"totalSold": { "$sum": "$Sold" }
}
},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$totalSold"
}
}
]
result = list(sales.aggregate(pipeline))
print(result)
اجرای این کوئری تجمیع نتایج زیر را به دست می دهد که مشابه نتایج حاصل از رویکرد MapReduce است:
[{
'Section': 'Nike',
'TotalSold': 12
},{
'Section': 'Adidas',
'TotalSold': 9
}]
عملکرد و سرعت پرس و جو
خط لوله تجمع نسخه به روز شده MapReduce است. MongoDB استفاده از خط لوله تجمیع را به جای MapReduce توصیه می کند، زیرا اولی کارآمدتر است.
ما سعی کردیم در حین اجرای پرسوجوهای بخش قبل، این ادعا را مطرح کنیم. و هنگامی که در یک دستگاه رم 12 گیگابایتی در کنار هم اجرا می شد، خط لوله تجمیع سریعتر به نظر می رسید، به طور متوسط 0.014 ثانیه در طول اجرا. برای اجرای پرس و جو MapReduce از همان دستگاه به طور متوسط 0.058 ثانیه طول کشید.
این معیاری برای نتیجه گیری در مورد عملکرد آنها نیست، اما به نظر می رسد که از توصیه MongoDB پشتیبانی می کند. ممکن است این اختلاف زمانی را ناچیز در نظر بگیرید، اما به طور قابل توجهی در هزاران یا میلیون ها پرس و جو جمع می شود.
مزایا و معایب MapReduce
مزایا و معایب MapReduce را در نظر بگیرید تا مشخص کنید که در پردازش دادهها در کجا برتر است.
طرفداران
- از آنجایی که نقشه را جداگانه می نویسید و عملکردها را کاهش می دهید، انعطاف بیشتری برای سفارشی سازی می دهد.
- شما به راحتی می توانید خروجی را در یک مجموعه جدید MongoDB در داخل پایگاه داده ذخیره کنید.
- می توانید از MapReduce در سیستم های فایل توزیع شده مانند Hadoop استفاده کنید که به راحتی با MongoDB ادغام می شود.
- پشتیبانی آن از اسکریپت نویسی شخص ثالث، یادگیری آن را مقیاس پذیرتر و آسان تر از خط لوله جمع آوری می کند. بنابراین شخصی با پیشینه توسعه جاوا اسکریپت می تواند MapReduce را پیاده سازی کند.
منفی
- به برنامه نویسی شخص ثالث نیاز دارد. این به عملکرد کمتر آن نسبت به خط لوله تجمع کمک می کند.
- MapReduce می تواند حافظه ناکارآمد باشد و به چندین گره نیاز دارد، مخصوصاً زمانی که با داده های بیش از حد پیچیده سروکار داریم.
- از آنجایی که پرس و جو می تواند کند باشد، برای پردازش داده های بلادرنگ مناسب نیست.
مزایا و معایب خط لوله تجمع
خط لوله تجمیع چطور؟ در نظر گرفتن نقاط قوت و ضعف آن بینش بیشتری را فراهم می کند.
طرفداران
- پرس و جو چند مرحله ای است، معمولاً کوتاه تر، مختصرتر و خواناتر است.
- خط لوله تجمع کارآمدتر است و نسبت به MapReduce پیشرفت قابل توجهی را ارائه می دهد.
- از اپراتورهای داخلی MongoDB پشتیبانی می کند که به شما امکان می دهد پرس و جو خود را انعطاف پذیر طراحی کنید.
- از پردازش داده ها در زمان واقعی پشتیبانی می کند.
- خط لوله تجمع به راحتی در MongoDB قابل جذب است و نیازی به اسکریپت شخص ثالث ندارد.
- در صورت نیاز به ذخیره کردن خروجی ها، می توانید یک مجموعه MongoDB جدید برای خروجی ها ایجاد کنید.
منفی
- ممکن است به اندازه MapReduce در هنگام برخورد با ساختارهای داده پیچیده تر انعطاف پذیر نباشد. از آنجایی که از برنامه نویسی شخص ثالث استفاده نمی کند، شما را به روش خاصی برای جمع آوری داده ها محدود می کند.
- پیادهسازی و منحنی یادگیری آن میتواند برای توسعهدهندگان با تجربه کم یا بدون تجربه MongoDB چالش برانگیز باشد.
چه زمانی باید از MapReduce یا Aggregation Pipeline استفاده کنید؟

به طور کلی، بهتر است هنگام انتخاب بین MapReduce و خط لوله تجمع، نیازهای پردازش داده خود را در نظر بگیرید.
در حالت ایدهآل، اگر دادههای شما پیچیدهتر است و به منطق و الگوریتمهای پیشرفته در یک سیستم فایل توزیعشده نیاز دارد، MapReduce میتواند مفید باشد. این به این دلیل است که می توانید به راحتی توابع کاهش نقشه را سفارشی کنید و آنها را به چندین گره تزریق کنید. اگر وظیفه پردازش داده شما به مقیاس افقی بیش از کارایی نیاز دارد، به MapReduce بروید.
از سوی دیگر، خط لوله تجمع برای محاسبه داده های پیچیده که به منطق یا الگوریتم های سفارشی نیاز ندارند، مناسب تر است. اگر دادههای شما فقط در MongoDB هستند، استفاده از خط لوله جمعآوری منطقی است زیرا دارای اپراتورهای داخلی بسیاری است.
خط لوله تجمیع همچنین برای پردازش داده های بلادرنگ بهترین است. اگر نیاز محاسباتی شما کارایی را بر سایر عوامل ترجیح می دهد، می خواهید خط لوله تجمیع را انتخاب کنید.
محاسبات پیچیده را در MongoDB اجرا کنید
اگرچه هر دو روش MongoDB کوئری های پردازش داده های بزرگ هستند، اما تفاوت های زیادی با یکدیگر دارند. به جای بازیابی داده ها قبل از انجام محاسبات، که می تواند کندتر باشد، هر دو روش مستقیماً محاسبات را روی داده های ذخیره شده در پایگاه داده انجام می دهند و پرس و جوها را کارآمدتر می کنند.
با این حال، یکی در عملکرد جایگزین دیگری می شود، و شما درست حدس زدید. خط لوله تجمیع در کارایی و عملکرد بر MapReduce برتری دارد. اما در حالی که ممکن است بخواهید به هر قیمتی MapReduce را با خط لوله تجمیع جایگزین کنید، هنوز حوزههای کاربردی خاصی وجود دارد که استفاده از MapReduce منطقیتر است.